Deducing Types
Item 1: Understand template type deduction
예를 들어 함수 템플릿 선언이 다음과 같다고 하자.
template<typename T>
void f(const T& param); // ParamType is const T&
그리고 이를 다음과 같이 호출한다.
int x = 0;
f(x); // call f with an int
이 경우 T는 int로 추론되나 ParamType은 const int&로 추론된다.
T에 대해 추론된 타입은 expr 타입 뿐만 아니라 ParamType의 타입에도 의존한다. 타입에 따라 총 3가지 경우로 나뉜다.
ParamType이 포인터 또는 참조 형식이지만 보편 참조(universal reference)는 아닌 겨웅ParamType이 보편 참조인 경우ParamType이 포인터도 아니고 참조도 아닌 경우
경우 1: ParamType이 포인터 또는 참조 타입이지만 보편 참조는 아님
이 경우 타입 추론은 다음과 같이 진행된다.
expr이 참조 형식이면 참조 부분을 무시- 그 다음
epxr의 타입을ParamType에 대해 패턴 매칭 방식으로 대응시켜T타입을 결정
함수 템플릿이 다음과 같고
template<typename T>
void f(T& param); // param is a reference
다음과 같은 변수 선언들이 있고, 추론되었다고 하자.
int x = 27; // x is an int
const int cx = x; // cx is a const int
const int& rx = x; // rx is a reference to x as a const int
f(x); // T is int, param's type is int&
f(cx); // T is const int, param's type is const int&
f(rx); // T is const int, param's type is const int&
둘째, 셋째 호출에서 cx와 rx가 const 값이기 때문에 T가 const int로 추론되었다. 셋째 호출에서 rx의 타입이 참조이지만 T는 비참조로 추론되었다. 이는 타입 추론 과정에서 rx의 참조성(reference-ness)이 무시되기 때문이다.
경우 2: ParamType이 보편 참조임
보편 참조 매개변수의 선언은 오른값 참조와 같은(T&&) 모습이지만, 왼값 인수가 전달되면 오른값 참조와는 다른 방식으로 행동한다.
template<typename T>
void f(T&& param); // param is now a universal reference
expr이 왼값이면,T와ParamType둘 다 왼값 참조로 추론된다.expr이 오른값이면 정상적인 규칙(경우 1)이 적용된다.
f(x); // x is lvalue, so T is int&, param's type is also int&
f(cx); // cx is lvalue, so T is const int&, param's type is also const int&
f(rx); // rx is lvalue, so T is const int&, param's type is also const int&
f(27); // 27 is rvalue, so T is int, param's type is therefore int&&
경우 3: ParamType이 포인터도 아니고 참조도 아님
이 경우 인수가 함수에 값으로 전달(pass-by-value)되는 상황이다.
template<typename T>
void f(T param); // param is now passed by value
따라서 param은 주어진 인수의 복사본, 즉 새로운 객체이다. 그러므로 expr에서 T가 추론되는 과정에서 다음과 같은 규칙이 적용된다.
expr의 타입이 참조이면 참조 부분은 무시된다.2expr의 참조성을 무시한 후, 만약expr이const라면 그const역시 무시한다. 만일volatile이면 이것도 무시한다.
f(x); // T's and param's types are both int
f(cx); // T's and param's types are again both int
f(rx); // T's and param's types are still both int
배열 인수
배열을 값 전달 매개변수를 받는 템플릿에 전달하면
const char * ptrToName = name;
template<typename T>
void f(T param); // template with by-value parameter
f(name); // what types are deduced for T and param?
타입 매개변수 T는 const char*로 추론된다(name은 배열이지만).
비록 함수의 매개변수를 진짜 배열로 선언할 수 없지만, 배열에 대한 참조로는 선언할 수 있다. 즉, 다음처럼 템플릿 f가 인수를 참조로 받도록 수정하고
template<typename T>
void f(T& param); // template with by-reference parameter
f 함수에 배열(name)을 전달하면 T에 대해 추론된 타입은 배열의 실제 타입이 된다. 이 타입은 배열의 크기를 포함하므로, T는 const char [13]으로 추론되고, f의 매개변수 타입은 const char (&)[13]으로 추론된다.
함수 인수
함수 타입도 함수 포인터로 추론될 수 있으며, 배열에 대한 타입 추론과 동일하게 적용된다.
Item 2: Understand auto type deduction
템플릿 타입 추론과 auto 타입 추론은 알고리즘적으로 상호 변환이 가능하다.
template<typename T>
void f(ParamType param);
f(expr); // call f with some expression
f를 호출할 때 컴파일러는 expr을 이용해 T의 타입과 ParamType을 추론한다.
auto를 이용해 변수를 선언할 때 auto는 템플릿의 T와 동일한 역할을 하며, 변수의 타입 지정자(type specifier)는 ParamType과 동일한 역학을 한다.
auto x = 27;
const auto cx = x; // type specifier is const auto
const auto& rx = x; //type specifier is const auto &
x, cx, rx의 타입들을 추론할 때, 컴파일러는 마치 선언마다 템플릿 함수 하나와 해당 초기화 표현식으로 그 템플릿 함수를 호출하는 구문이 존재하는 것처럼 행동한다.
template<typename T> // conceptual template for deducing x's type
void func_for_x(T param);
func_for_x(27); // conceptual call: param's deduced type is x's type
template<typename T> // conceptual template for deducing cx's type
void func_for_cx(const T param);
func_for_cx(x); // conceptual call: param's deduced type is cx's type
template<typename T> // conceptual template for deducing rx's type
void func_for_rx(const T& param);
func_for_rx(x); // conceptual call: param's deduced type is rx's type
auto의 타입 추론은 템플릿 타입 추론과 동일하게 작동한다.
그러나 다른 점이 있다. int 변수를 선언하는 예를 보면, 아래의 두 선언은 값이 27인 원소 하나를 담은 std::initializer_list<int> 타입의 변수를 선언한다.
auto x1 = 27; // type is int, value is 27
auto x2(27); // ditto
auto x3 = { 27 }; // type is std::initializer_list<int>, value is { 27 }
auto x4{ 27 }; // ditto
이는 auto에 대한 특별한 타입 추론 규칙 때문이다. auto로 선언된 변수의 초기치(initializer)가 중괄호 쌍으로 감싼 형태이면, 추론된 타입은 std::initiazlier_list이다. 만약 이런 타입을 추론할 수 없으면 컴파일이 거부된다.
C++14에서는 함수의 반환 타입을 auto로 지정해 컴파일러가 추론하게 만들 수 있으며, 람다의 매개변수 선언에 auto를 사용하는 것도 가능하다. 하지만 이 용법들에는 auto 타입 추론이 아니라 템플릿 타입 추론 규칙이 적용된다.
Item 3: Understand decltype
decltype은 주어진 이름이나 표현식의 타입을 알려준다.
decltype은 반환 타입이 그 매개변수 타입들에 의존하는 함수 템플릿을 선언할 때 주로 사용된다.
template<typename Container, typename Index> // works, but requires refinement
auto authAndAccess(Container& c, Index i)
-> decltype(c[i])
{
authenticateUser();
return c[i];
}
함수 이름 앞에 있는 auto는 타입 추론과는 관련이 없다. 이 auto는 여기에 후행 반환 타입(trailing return type) 구문이 쓰인다는 것을 나타낸다. 즉, 반환 타입을 이 위치가 아니라 매개변수 목록 다음(->) 선언하겠다는 점을 나타낸다. 이러한 후행 반환 타입을 매개변수들을 이용해 지정할 수 있다는 장점이 있다. 위 예에서는 c와 i를 이용해 반환 타입을 지정했다.
C++14에서는 후행 반환 타입(-> decltype(c[i]))을 생략하고 그냥 함수 이름 앞에 auto만 남겨도 된다. 이러한 형태의 선언에서는 실제로 auto가 타입 추론이 일어나는 것을 의미한다.
Item 2에서 설명했듯, 함수의 반환 타입에 auto가 지정되어 있으면 컴파일러는 템플릿 타입 추론을 적용한다. T 객체들을 담은 컨테이너에 대한 operator[] 연산은 대부분의 경우 T&를 반환한다. 그러나 문제는 Item 1에서 설명했듯 템플릿 타입 추론 과정에서 초기화 표현식의 참조성이 무시된다는 것이다.
std::deque<int> d;
...
authAndAccess(d, 5) = 10; // authenticate user, return d[5],
// then assign 10 to it;
// this won't compile!
d[5]는 int&를 돌려주지만, authAndAccess()에 대한 auto 반환 타입이 타입 추론 과정에서 참조가 제거되기 때문에 결국 반환 타입은 int가 된다. 이 값은 rvalue이며 결과적으로 rvalue에 10을 할당하려 하기 때문에 컴파일이 되지 않는다.
따라서 authAndAccess()가 c[i]의 반환 타입과 동일한 타입을 반환하게 만들어야 한다. 이는 decltype(auto) 지정자를 통해 가능하게 만들 수 있다. auto는 해당 타입이 추론되어야 함을 뜻하고, decltype은 추론 과정에서 decltype 타입 추론 규칙이 적용되어야 함을 뜻한다.
template<typename Container, typename Index> // C++14; works, but still requires refinement
decltype(auto)
authAndAccess(Container& c, Index i)
{
authenticateUser();
return c[i];
}
다음은 C++14 버전의 authAndAccess() 선언이다.
template<typename Container, typename Index>
decltype(auto) authAndAccess(Container& c, Index i);
Item 4: Know how to view deduced types
컴파일러가 추론하는 타입을 IDE 편집기나 컴파일러 오류 메시지, Boost.TypeIndex 라이브러리를 이용해 파악할 수 있는 경우가 많다.
auto
Item 5: Prefer auto to explicit type declarations
auto 타입은 해당 초기치로부터 추론되므로, 반드시 초기치를 제공해야 한다. 따라서 초기화를 빼먹는 실수를 저지를 여지가 사라진다.
지역 변수 선언에서 변수의 값을 반복자 역참조로 초기화하는 것도 가능하다.
template<typename It> // as before
void dwim(It b, It e)
{
while (b != e) {
auto currValue = *b; // typename std::iterator_traits<It>::value_type => auto
...
}
}
그리고 auto는 타입 추론을 사용하므로(Item 2), 예전에는 컴파일러만 알던 타입을 지정할 수 있다.
auto derefUPLess = // comparison func.
[](const std::unique_ptr<Widget>& p1, // for Widgets
const std::unique_ptr<Widget>& p2) // pointed to by
{ return *p1 < *p2; }; // std::unique_ptrs
std::function은 호출 가능한 객체이면 어떤 것도 가리킬 수 있다.
bool(const std::unique_ptr<Widget>&, // C++11 signature for
const std::unique_ptr<Widget>&) // std::unique_ptr<Widget>
// comparison function
위 함수 시그니처에 해당하는 std::function을 생성한다고 하면 다음과 같을 것이다.
std::function<bool(const std::unique_ptr<Widget>&,
const std::unique_ptr<Widget>&)> func;
람다 표현식이 산출하는 클로저는 호출 가능 객체이므로, std::function 객체에 저장할 수 있다.
std::function<bool(const std::unique_ptr<Widget>&,
const std::unique_ptr<Widget>&)>
derefUPLess = [](const std::unique_ptr<Widget>& p1,
const std::unique_ptr<Widget>& p2)
{ return *p1 < *p2; };
이 때 std::function을 사용하는 것과 auto로 선언하는 것 사이 중요한 차이가 있다.
auto로 선언된 그리고 클로저를 담는 변수는 그 클로저와 같은 형식이며, 따라서 그 클로저에 요구되는 만큼의 메모리만 사용한다.
그러나 클로저를 담는 std::function으로 선언된 변수 타입은 std::function 템플릿의 한 인스턴스이며, 이 크기는 임의의 주어진 시그니처에 대해 고정되어 있다. 그런데 이 크기는 요구된 클로저를 저장하기에 부족할 수 있으며, 이런 경우 std::function은 힙 메모리를 할당해 클로저를 저장한다.
즉, std::function 객체는 auto로 선언된 객체보다 메모리를 더 많이 소비한다. 그리고 인라인화(inlining)를 제한하고 간접 함수 호출을 산출하는 구현 세부사항 때문에 std::function 객체를 통해 클로저를 호출하는 것은 거의 항상 auto로 선언된 객체를 통해 호출하는 것보다 느리다.
Item 6: Use the explicitly typed initializer idiom when auto deduces undesired types
Widget을 받아서 std::vector<bool>을 돌려주는 함수가 있다고 하자.
Widget w; ...
bool highPriority = features(w)[5]; // is w high priority?
processWidget(w, highPriority); // process w in accord
// with its priority
highPriority의 명시적 타입을 auto로 대체하면 상황이 달라진다. 컴파일은 되나 그 행동을 예측할 수 없다.
auto highPriority = features(w)[5]; // is w high priority?
processWidget(w, highPriority); // undefined behavior!
auto를 사용하는 버전에서 highPriority 타입은 더 이상 bool이 아니다.
std::vector<bool>은 bool을 담는 컨테이너다. 그러나 std::vector<bool>의 operator[]가 돌려주는 것은 그 컨테이너의 한 요소에 대한 참조가 아닌, std::vector<bool>::reference 타입(std::vector<bool> 안에 내포된 클래스)의 객체이다.
std::vector<bool>::reference가 존재하는 것은 std::vector<bool>이 자신의 bool들을 bool 당 1비트의 압축된 타입으로 표현하도록 명시되어 있기 때문이다. 따라서 operator[]를 직접 구현할 수 없다. std::vector<T>의 operator[]는 T&를 돌려주지만, C++에서 비트에 대한 참조는 금지되어 있다. 따라서 std::vector<bool>의 operator[]는 마치 bool&처럼 작동하는 객체를 돌려주도록 우회책을 사용한 것이다.
명시적 타입을 사용한 경우(bool highPriority) features()는 std::vector<bool> 객체를 돌려주며, 이 객체에 대해 operator[]가 호출된다. operator[]는 std::vector<bool>::reference를 돌려주며, 이 객체가 암묵적으로 bool로 변환되어 5번 비트가 highPriority 초기화에 쓰인다.
au to를 사용할 경우(auto highPriority) std::vector<bool>::reference 객체를 돌려주는 것 까지는 동일하다. 그러나 auto에 의해 highPriority 타입이 추론되기 때문에 std::vector<bool> 타입의 5번 비트로 초기화되지 않게 된다.
이때 highPriority가 가지는 값은 std::vector<bool>::reference 구현 방식에 따라 다르다. 이 구현 방식 중 하나는 그 객체의 참조된 비트를 담은 기계어 워드(word)를 가리키는 포인터 하나와 이 워드의 비트들 중 참조된 비트의 위치를 뜻하는 오프셋으로 구성된다. 이 경우 features()는 임시 std::vector<bool> 객체(temp라 하자)를 돌려주며, 이 객체에는 temp가 관리하는 비트들을 담은 자료구조의 한 워드를 가리키는 포인터와 그 워드에서 참조된 비트(5번)에 해당하는 비트의 오프셋이 담겨 있다. 따라서 highPriority는 std::vector<bool>::reference 객체의 한 복사본이며, highPriority 역시 temp 안의 해당 워드를 가리키는 포인터와 5번 비트 오프셋을 담게 된다. 즉, highPriority의 포인터는 댕글링 포인터가 되며 미정의 행동을 유발한다.
std::vector<bool>::reference는 프록시 클래스(프록시 패턴), 즉 어떤 형식을 흉내내고 보강하는 것이 존재 이유인 클래스다. 프록시 패턴 중 클라이언트에게 명백히 드러나도록 설계된 것의 대표적인 예로 std::shared_ptr, std::unique_ptr가 있다. 반면 다른 프록시 패턴들은 다소 은밀하게 동작되도록 설계되었다.
이러한 보이지 않는 프록시 클래스는 auto와 잘 맞지 않는다.
보통 프록시 클래스는 그 존재가 드러나지 않도록 설계되었지만, 그래도 라이브러리 문서에서 프록시 클래스의 존재가 명시되어 있는 경우가 많다. 이러한 방식을 통해 auto가 프록시 클래스 타입을 추론한다는 것을 알았다고 하자. 이때 auto가 다른 타입을 추론하도록 강제할 수 있다.
explicitly typed initializer idiom.
변수를 auto로 선언하되 초기화 표현식의 타입을 auto가 추론하길 원하는 타입으로 캐스팅한다.
auto highPriority = static_cast<bool>(features(w)[5]);
이전과 같이 std::vector<bool>::reference를 돌려주나, 캐스팅 때문에 표현식 타입은 bool이 되어, std::vector<bool>::operator[]가 돌려준 std::vector<bool>::reference 객체는 자신이 지원하는 bool로의 변환을 수행하며, 그 변환 도중 features()가 돌려주는 std::vector<bool>을 가리키는 포인터가 역참조된다. 이 시점에서 포인터는 여전히 유효하므로, 미정의 행동 이슈는 더 이상 발생하지 않는다.
Moving to Modern C++
Item 7: Distinguish between () and {} when creating objects
C++11에서는 중괄호 초기화(uniform initialization)을 도입했다. 어디서나 사용할 수 있고 모든 것을 표현할 수 있는 초기화 구문이다.
int x(0); // initializer is in parentheses
int y = 0; // initializer follows "="
int z{ 0 }; // initializer is in braces
int z = { 0 }; // initializer uses "=" and braces
복사할 수 없는 객체(std::atomic)는 중괄호나 괄호로는 초기화할 수 있지만, =로는 초기화할 수 없다.
std::atomic<int> ai1{ 0 }; // fine
std::atomic<int> ai2(0); // fine
std::atomic<int> ai3 = 0; // error!
중괄호 초기화 기능 중 하나는 내장 기능들 사이 암묵적 좁히기 변환(narrowing conversion)을 방지해준다는 것이다. 중괄호 초기치에 있는 어떤 표현식의 값을 초기화하려는 객체의 타입으로 온전히 표현할 수 있음이 보장되지 않는 경우, 컴파일러는 그 사실을 보고해야 한다.
double x, y, z;
...
int sum1{ x + y + z }; // error! sum of doubles may not be expressible as int
중괄호 초기화의 또 다른 주목할 점은 most vexing parse에서 자유롭다는 것이다. most vexing parse는 “선언으로 해석할 수 있는 것은 항상 선언으로 해석해야 한다.“는 C++ 규칙에서 비롯된 하나의 부작용인데, 기본 생성자를 이용해 객체를 생성하려 했지만 의도와 달리 함수를 선언하게 되었을 때 이를 경험한 것이다.
Widget w2(); // most vexing parse! declares a function
// named w2 that returns a Widget!
중괄호를 이용해 객체를 생성할 때는 이런 문제를 겪지 않는다.
auto를 사용한 중괄호 초기화에서 std::initializer_list 타입으로 추론되는 경우가 많다. 생성자 호출에서 std::initializer_list 매개변수가 관여하지 않는 한 괄호와 중괄호의 의미는 같다.
그러나 생성자 중 하나 이상이 std::initializer_list 타입의 매개변수를 선언한다면, 중괄호 초기화 구문은 std::initializer_list를 받는 오버로딩 버전을 강하게 선호한다. 중괄호 초기치가 쓰인 호출을 std::initializer_list를 받는 버전의 생성자 호출로 해석할 여지가 조금이라도 있다면 컴파일러느 반드시 그 해석을 선택한다.
class Widget {
public:
Widget(int i, bool b); // as before
Widget(int i, double d); // as before
Widget(std::initializer_list<long double> il); // added ...
};
Widget w1(10, true); // uses parens and, as before, calls first ctor
Widget w2{10, true}; // uses braces, but now calls std::initializer_list ctor
// (10 and true convert to long double)
Widget w3(10, 5.0); // uses parens and, as before, calls second ctor
// uses braces, but now calls
Widget w4{10, 5.0}; // std::initializer_list ctor
// (10 and 5.0 convert to long double)
컴파일러는 중괄호 초기치의 인수 타입들을 std::initializer_list 안의 타입으로 아예 변환할 수 없을때에만 다른 생성자를 선택한다.
또 하나 흥미로운 경우를 보면, 기본 생성을 지원하며 std::initializer_list 생성도 지원하는 객체를 빈 중괄호 쌍으로 생성한다고 하자. 표준에 따르면 컴파일러는 기본 생성자가 호출된다. 즉, 빈 중괄호 쌍은 빈 std::initializer_list가 아니라 인수 없음을 뜻한다.
Widget w1; // calls default ctor
Widget w2{}; // also calls default ctor
Widget w3(); // most vexing parse! declares a function!
std::initializer_list 생성자를 호출하고 싶다면 빈 중괄호 쌍을 괄호로 감싸거나(Widget w4({});), 빈 중괄호 쌍을 또 다른 중괄호 쌍으로 감싸면(Widget w5{{}};) 된다.
결과적으로 클래스 사용자로서 객체를 생성할 때는 괄호와 중괄호를 세심하게 선택해야 한다. 두 방식 모두 장단점이 있으므로 둘 중 하나를 선택해 일관되게 적용하도록 하자.
Item 8: Prefer nullptr to 0 and NULL
nullptr은 정수 타입 또는 포인터 타입이 아니다. nullptr의 실제 타입은 std::nullptr_t인데 std::nullptr_t 자체는 다시 nullptr의 타입으로 정의된다. std::nullptr_t는 모든 raw pointer 타입으로 암묵적으로 변환되며, 따라서 nullptr은 마치 모든 타입의 포인터처럼 행동한다.
auto result = findRecord( /* arguments */ );
if (result == nullptr) {
...
}
findRecord()의 타입을 모른다면 result가 포인터 타입인지 정수 타입인지 명확히 알 수 없다. 따라서 result == 0인 경우 0은 포인터 타입으로도, 정수 타입으로도 작용할 수 있다. 하지만 result == nullptr 같은 코드는 중의성이 없으며 result는 포인터 타입임이 명확하다.
다음 템플릿을 보자.
template<typename FuncType,
typename MuxType,
typename PtrType>
decltype(auto) lockAndCall(FuncType func, // C++14
MuxType& mutex,
PtrType ptr)
{
MuxGuard g(mutex);
return func(ptr);
}
auto result1 = lockAndCall(f1, f1m, 0); // error!
auto result2 = lockAndCall(f2, f2m, NULL); // error!
auto result3 = lockAndCall(f3, f3m, nullptr); // fine
lockAndCall()에 0을 전달하면 0의 타입을 파악하기 위해 템플릿 타입 추론을 수행하는데, 0의 타입은 항상 int이므로 매개변수와 호환되지 않아 컴파일 오류가 발생한다. NULL 또한 동일한 이유로 오류를 발생시킨다.
반면, nullptr은 std::nullptr_t로 추론되고, ptr을 func에 전달하면 std::nullptr_t에서 Widget*으로 암묵적 변환이 일어난다. std::nullptr_t는 암묵적으로 모든 포인터 타입으로 변환되기 때문이다.
Item 9: Prefer alias declarations to typedefs
typedef를 사용해 간단하게 표현할 수 있지만, 이는 C++98의 유물이다.
typedef
std::unique_ptr<std::unordered_map<std::string, std::string>>
UPtrMapSS;
C++11에서도 typedef가 동작하나 별칭 선언(alias declaration)도 제공하고 있다. typedef와 별칭 선언이 하는 일을 정확히 동일하다.
using UPtrMapSS =
std::unique_ptr<std::unordered_map<std::string, std::string>>;
별칭 선언이 강력한 이유는 템플릿에 있다. typedef는 템플릿화할 수 없지만, 별칭 선언은 템플릿화할 수 있다.
MyAlloc이라는 커스텀 할당자를 사용하는 링크드 리스트의 동의어를 정의한다고 하자. using을 사용할 경우 간단하지만
template<typename T> // MyAllocList<T>
using MyAllocList = std::list<T, MyAlloc<T>>; // is synonym for
// std::list<T, MyAlloc<T>>
MyAllocList<Widget> lw; // client code
typedef 버전은 템플릿화가 불가능해 복잡한 구조가 된다.
template<typename T> // MyAllocList<T>::type
struct MyAllocList { // is synonym for
typedef std::list<T, MyAlloc<T>> type; // std::list<T, MyAlloc<T>>
};
MyAllocList<Widget>::type lw; // client code
또한 템플릿 매개변수로 지정된 타입의 객체들을 담는 링크드 리스트를 생성하려는 목적으로 템플릿 안에서 typedef를 사용하려면 typename를 붙여야 한다.
template<typename T>
class Widget { // Widget<T> contains
private: // a MyAllocList<T>
typename MyAllocList<T>::type list; // as a data member
...
};
여기서 MyAllocList<T>::type는 템플릿 타입 매개변수(T)에 의존적인 타입을 지칭한다.
MyAllocList를 별칭 선언으로 지정하면 typename을 붙일 필요가 없다.
template<typename T>
using MyAllocList = std::list<T, MyAlloc<T>>; // as before
template<typename T>
class Widget {
private:
MyAllocList<T> list; // no "typename", no "::type"
...
};
MyAllocList<T>는 템플릿 매개변수 T에 의존하는 것 같지만, 컴파일러는 그렇게 여기지 않는다. 컴파일러가 Widget을 처리하는 과정에서 MyAllocList<T>에 도달했을 때, 컴파일러는 이 MyAllocList<T>가 타입의 이름임을 이미 알고 있다. 즉, MyAllocList<T>는 비의존적 타입이므로 typename 지정자를 붙일 필요가 없다.
반면, Widget 템플릿 안에서 MyAllocList<T>::type을 만난 컴파일러는 이 타입이 이름임을 확신하지 못한다(Effective C++ Item 42 참고).
Item 10: Prefer scoped enums to unscoped enums
일반적으로 중괄호 쌍 안에서 어떤 이름을 선언하면 그 이름의 가시성은 해당 중괄호 쌍이 정의하는 범위로 한정된다. 그러나 C++98 스타일의 enum으로 선언된 열거자(enumerator)는 이런 규칙이 적용되지 않는다. 이런 종류의 enum을 범위 없는(unscoped) enum이라 한다.
이에 대응되는 C++11의 범위 있는(scoped) enum에서는 이름 누수가 발생하지 않는다.
enum class Color { black, white, red }; // black, white, red are scoped to Color
auto white = false; // fine, no other "white" in scope
Color c = white; // error! no enumerator named "white" is in this scope
Color c = Color::white; // fine
auto c = Color::white; // also find (and in accord with Item 5's advice)
enum class의 또 다른 장점으로 타입에 더 강력하게 적용된다는 것이다. enum은 암묵적으로 정수 타입으로 변환되어 다음과 같은 코드를 만났을 때 의미론적 재앙이 유효하다.
Color c = red;
if (c < 14.5) { // compare Color to double (!)
auto factors = // compute prime factors of a Color (!)
primeFactors(c);
...
}
그러나 enum class는 암묵적으로 다른 타입으로 변환되지 않아 위와 같은 문제는 발생되지 않는다.
추가로 enum class는 전방 선언(forward declaration)이 가능하다. 즉, 열거자들을 지정하지 않고 열거형 이름만 미리 선언할 수 있다. 따라서 전방 선언된 enum class를 포함하는 헤더는 다시 컴파일하지 않아도 된다.
enum Color; // error!
enum class Color; // fine
Item 11: Prefer deleted functions to private undefined ones
C++98에서는 사용을 금지하려는 멤버 함수(복사 생성자, 복사 할당자 등)들을 private으로 선언하고 정의하지 않는 방식을 사용했다.
iostream 계통 구조의 뿌리 부근에는 basic_ios라는 클래스 템플릿이 있다. 여기서 입력 스트림이나 출력 스트림 객체는 복사하지 않는 것이 좋은데, 이는 그 객체에 대한 복사 연산이 구체적으로 어떤 일을 해야 할 것인지가 명확하지 않기 때문이다.
입출력 스트림 클래스들의 복사를 방지하기 위해 C++98에서는 private 섹션에 선언만 수행한다.
C++11에서는 같은 목적을 달성하기 위해 = delete를 사용한다.
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
...
basic_ios(const basic_ios& ) = delete;
basic_ios& operator=(const basic_ios&) = delete;
...
};
삭제된 함수는 어떤 방법으로든 사용할 수 없다.
삭제할 함수는
private이 아니라public으로 선언하는 것이 관례이다.
배제할 타입들에 대해 함수 오버로딩을 명시적으로 삭제하여 컴파일되지 않도록 할 수 있다.
bool isLucky(int number); // original function
bool isLucky(char) = delete; // reject chars
bool isLucky(bool) = delete; // reject bools
bool isLucky(double) = delete; // reject doubles and floats
char*(C 스타일 문자열), void*(역참조나 증가, 감소가 불가)와 같이 특별한 포인터들을 처리가 필요한 경우가 많은데, processPointer() 템플릿은 이 타입들을 이용한 호출을 아예 거부하는 것이라 하자. 단순히 템플릿 인스턴스들을 삭제하면 된다.
template<>
void processPointer<void>(void*) = delete;
template<>
void processPointer<char>(char*) = delete;
Item 12: Declare overriding functions override
가상 함수 재정의는 파생 클래스 함수를 기반 클래스의 인터페이스를 통해 호출할 수 있게 만드는 메커니즘이다.
재정의가 일어나려면 다음과 같은 조건을 만족해야 한다.
- 기반 클래스 함수가 반드시 가상 함수여야 한다.
- 기반 함수와 파생 함수의 이름이 반드시 동일해야 한다.
- 기반 함수와 파생 함수의 매개변수 타입들이 동일해야 한다.
- 기반 함수와 파생 함수의 상수(const)성이 반드시 동일해야 한다.
- 기반 함수와 파생 함수의 반환 타입과 예외 명세가 반드시 호환되어야 한다.
- 멤버 함수들의 참조 한정사(reference qualifier)들이 반드시 동일해야 한다. 멤버 함수 참조 한정사 기능을 이용하면 멤버 함수를 왼값에만 또는 오른값에만 사용할 수 있게 제한할 수 있다(C++11).
- 기반 클래스의 가상 함수에 참조 한정사가 있으면, 그 함수를 재정의하는 파생 클래스의 함수에도 정확히 같은 참조 한정사가 있어야 한다는 것을 기억하자.
class Base {
public:
virtual void mf1() const;
virtual void mf2(int x);
virtual void mf3() &;
virtual void mf4() const;
};
class Derived: public Base {
public:
virtual void mf1() const override;
virtual void mf2(int x) override;
virtual void mf3() & override;
void mf4() const override; // adding "virtual" is OK, but not necessary
};
Item 13: Prefer const_iterators to iterators
const_iterator는 const를 가리키는 포인터의 STL 버전이다. C++11에서는 const_iterator를 C++98에 비해 얻기도 쉽고 사용하기도 쉽다. cbegin(), cend()는 const_iterator를 반환한다. 삽입, 삭제 위치를 지정하는 목적으로 반복자를 사용하는 STL 멤버 함수들은 const_iterator를 사용한다.
다음은 const_iterator를 C++98 코드에서 사용하는 실용적인 코드이다.
std::vector<int> values; // as before ...
auto it = // use cbegin
std::find(values.cbegin(),values.cend(), 1983); // and cend
values.insert(it, 1998);
Item 14: Declare functions noexcept if they won’t emit exceptions
C++11에서는 함수가 예외를 하나라도 던질 수 있는지 아니면 절대 던지지 않는지 이분법적 논리를 적용했다. C++11에서 함수 선언 시 그 함수가 예외를 방출하지 않을 것임을 명시할 때 noexcept라는 키워드를 사용하면 된다.
함수를 noexcept로 선언할 것인지 여부는 인터페이스 설계상의 문제다. 함수의 예외 방출은 클라이언트에게는 아주 중요한 사항이다. 함수의 호출자는 함수의 noexcept 여부를 조회할 수 있으며, 그 조회 결과는 호출 코드의 예외 안정성이나 효율성에 영향을 미친다.
예외를 방출하지 않는 함수에 noexcept를 적용하면 컴파일러가 더 나은 목적 코드(object code)를 산출할 수 있다. 예를 들어 함수 f()를 호출했을 때 호출자가 예외를 받는 일이 결코 없음을 약속하는 것을 표현하는 방법은 두 가지다.
int f(int x) throw(); // no exceptions from f: C++98 style
int f(int x) noexcept; // no exceptions from f: C++11 style
C++98에서는 예외 명세가 위반되면 호출 스택이 f()를 호출한 지점에 도달할 때까지 풀리며(unwind), 그 지점에서 몇 가지 동작이 취해진 후 프로그램이 종료된다.
C++11에서는 프로그램 실행이 종료되기 전 호출 스택이 풀릴 수도 있고, 되지 않을 수도 있다. 이는 컴파일러 코드 작성이 큰 영향을 미친다. noexcept 함수에서 컴파일러의 최적화는 예외 함수가 바깥으로 전파될 수 있다고 해도 런타임 스택을 풀기 가능한 상태로 유지할 필요가 없다. 또한 예외가 noexcept 함수를 벗어난다고 해도 noexcept 함수 안 객체들을 반드시 생성 반대 순서로 파괴해야 하는 것도 아니다. 예외 명세가 throw이거나 명세가 아예 없는 함수는 이런 최적화 유연성이 없다.
RetType function(params) noexcept; // most optimizable
RetType function(params) throw(); // less optimizable
RetType function(params); // less optimizable
대부분의 함수는 예외에 중립적(exception-neutral) 이다. 예외 중립적 함수는 스스로 예외를 던지지 않지만, 예외를 던지는 다른 함수를 호출할 수 있다. 어떤 함수가 예외를 던지면 예외 중립적 함수는 그 예외를 그대로 통과시킨다. 따라서 예외 중립적 함수는 결코 noexcept가 될 수 없다.
noexcept로 선언하는 것이 중요한 일부 함수들은 기본적으로noexcept로 선언된다. 기본적으로 메모리 해제 함수와 모든 소멸자는 암묵적으로noexcept다. 따라서 이런 함수들은 직접noexcept로 선언할 필요가 없다.
라이브러리 인터페이스 설계자들 중 넓은 계약(wide contract)들을 가진 함수와 좁은 계약(narrow contract)들을 가진 함수를 구분하는 사람들이 있다.
- 넓은 계약을 가진 함수는 전제조건이 없는 함수를 말한다. 이런 함수는 프로그램 상태와는 무관하게 호출할 수 있으며, 호출자가 전달하는 인수에 어떠한 제약도 가하지 않는다. 넓은 계약 함수는 미정의 행동을 보이지 않는다.
- 넓은 계약을 가진 함수가 아닌 함수들은 모두 좁은 계약을 가진 함수이다. 이런 함수의 경우 함수의 전제 조건이 위반되면 이 결과는 미정의 행동으로 나타난다.
넓은 계약을 가진 함수를 작성할 때, 이 함수가 예외를 던지지 않는다면 noexcept로 선언하는 것은 쉽다. 그러나 좁은 계약의 경우 조금 더 까다롭다. std::string 매개변수를 받는 f() 함수를 작성하는데, f() 구현이 결코 예외를 방출하지 않는다고 하자. 그렇다면 f()는 noexcept로 선언해야 한다.
그런데 f()에 std::string 매개변수 길이가 32자를 넘지 않아야 한다는 전제조건이 있다고 하자. 길이가 32를 넘는 std::string으로 호출한 결과는 미정의 행동에 해당한다. 때문에 f()는 이러한 전제조건을 점검해야 할 의무가 없다. 그렇다면 f()를 noexcept로 선언하는 것은 합당하다.
f()의 구현자가 전제조건 위반을 f()에서 직접 점검한다고 하자. “전제조건 위반” 예외를 던질 수 있지만, noexcept로 선언되어 있어 이 방법은 불가능할 수 있다. 따라서 설계자들은 넓은 계약을 가진 함수들에 대해서만 noexcept를 사용하려는 경향이 있다.
Item 15: Use constexpr whenever possible
constexpr이 적용된 객체는 실제로 const이며, 그 값은 컴파일 시점에 알려진다.
상수이자 컴파일 시점에서 알려진 정수 값을 C++에서 정수 상수 표현식(integral constant expression) 이 요구되는 문맥(배열 크기, 정수 템플릿 인수, 열거자 값, alignment 지정자 등)에서 사용할 수 있다. 이러한 변수를 constexpr로 선언하면 컴파일러는 이것이 컴파일 시점 상수임을 보장해준다.
int sz; // non-constexpr variable
...
constexpr auto arraySize1 = sz; // error! sz's value not known at compilation
std::array<int, sz> data1; // error! same problem
constexpr auto arraySize2 = 10; // fine, 10 is a compile-time constant
std::array<int, arraySize2> data2; // fine, arraySize2 is constexpr
모든
constexpr객체는const지만, 모든const객체가constexpr인 것은 아니다.
constexpr 함수는 다음과 같은 특징을 가진다.
-
컴파일 시점 상수를 요구하는 문맥에
constexpr함수를 사용할 수 있다. 이런 문맥에서constexpr함수에 넘겨주는 인수의 값이 컴파일 시점에 알려진다면, 함수 결과는 컴파일 도중 계산된다. 인수 값이 컴파일 시점에 알려지지 않는다면, 코드의 컴파일이 거부된다. -
컴파일 시점에 알려지지 않는 하나 이상의 값들로
constexpr함수를 호출하면 함수는 보통의 함수처럼 동작한다. 즉, 런타임에 계산된다. -
constexpr함수는 반드시 리터럴(literal) 타입들을 받고 돌려주어야 한다. C++14에서 모든 빌트인 타입이 리터럴 타입이며, 생성자와 적절한 멤버 함수들이constexpr인 사용자 타입도 리터럴 타입이 될 수 있다.class Point { public: constexpr Point(double xVal = 0, double yVal = 0) noexcept : x(xVal), y(yVal) {} constexpr double xValue() const noexcept { return x; } constexpr double yValue() const noexcept { return y; } };Point의 생성자를constexpr로 선언할 수 있는 이유는, 주어진 인수들이 컴파일 시점에 알려진다면 생성된Point객체의 자료 멤버들의 값 역시 컴파일 시점에 알려질 수 있기 때문이다.
constexpr은 객체나 함수의 인터페이스의 일부라는 점을 명심하자. constexpr를 지정한다는 것은 “이 함수(또는 객체)를 C++이 상수 표현식을 요구하는 문맥에서 사용할 수 있다"는 사실을 말하는 것이다.
Item 16: Make const member functions thread safe
다항식(Polynomial)을 표현하는 클래스가 있다고 하자. 이 클래스는 다항식의 근(root)들, 즉 다항식이 0으로 평가되는 값들을 계산하는 멤버 함수를 갖추어야 할 것이다. 중복된 계산을 피하기 위해 캐시에 저장해 돌려주도록 구현하는 것이 바람직하다.
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const
{
if (!rootsAreValid) { // if cache not valid
... // compute roots, store them in rootVals
rootsAreValid = true;
}
return rootVals;
}
private:
mutable bool rootsAreValid{ false }; // see Item 7 for info on initializers
mutable RootsType rootVals{};
};
roots()는 const로 선언되어 있어 자신이 속한 Polynomial 객체를 변경하지 않는다. 그러나 캐시를 위해선 rootVals와 rootsAreValid의 변경이 필요할 수 있다.
만약 두 스레드가 하나의 Polynomial 객체에 대해 roots를 동시에 호출한다고 한다.
Polynomial p;
// ...
/*----- Thread 1 ----- */ /*------- Thread 2 ------- */
auto rootsOfP = p.roots(); auto valsGivingZero = p.roots()
지금 예에서는 roots() 안에서 두 스레드 중 하나나 둘 다가 자료 멤버 rootVals와 rootsAreValid를 수정하려 할 수 있다. 이는 레이스 컨디션(race condition)이 발생할 수 있다는 것을 의미하며 의도하지 않은 동작을 유발할 수 있다.
이는 뮤텍스를 사용해 해결할 수 있다.
RootsType roots() const
{
std::lock_guard<std::mutex> g(m); // lock mutex
if (!rootsAreValid) { // if cache not valid compute/store roots
...
rootsAreValid = true;
}
return rootVals;
}
Item 17: Understand special member function generation
C++의 special member function들은 C++이 스스로 작성하는 멤버 함수(생성자, 소멸자, 복사 생성자, 복사 할당 연산자)들을 가리킨다. 이 함수들은 꼭 필요한 경우, 즉 이 함수들을 사용하는 클라이언트 코드가 존재할 때에만 작성된다.
C++11은 special member function에 두 가지를 추가했다.
- 이동 생성자(move constructor)
- 이동 할당 연산자(move assignment operator)
class Widget {
public:
...
Widget(Widget&& rhs); // move constructor
Widget& operator=(Widget&& rhs); // move assignment operator
...
};
이동 생성자는 주어진 파라미터 rhs의 자료 멤버들 각각 이동 생성하고, 이동 할당 연산자는 주어진 파라미터 rhs의 자료 멤버 각각을 이동 할당한다. 기반 클래스 부분도 동일하다.
복사 연산들과 동일하게 명시적으로 선언한 이동 연산들을 자동으로 작성되지 않는다. 그러나 이동 연산들이 작성되는 구체적인 조건은 복사 연산들과는 조금 다르다.
두 복사 연산들을 서로 독립적이다. 둘 중 하나를 선언했다고 해서 다른 하나의 작성이 방지되지 않는다. 예를 들어, 복사 생성자를 선언했지만 복사 할당 연산자를 선언하지 않았고, 복사 할당 연산이 필요한 클라이언트 코드를 작성했다면, 컴파일러가 자동으로 복사 할당 연산자를 작성한다.
그러나 두 이동 연산은 독립적이지 않다. 둘 중 하나를 선언하면 컴파일러는 다른 하나를 작성하지 않는다. 이런 규칙에 깔린 근거는 다음과 같다. 어떤 클래스에 대해 이동 생성자를 선언했다면, 이는 컴파일러가 작성해주는 기본적인 멤버 이동 생성이 해당 클래스에 적합하지 않아 다른 방식으로 구현해야 하기 때문일 것이다. 그리고 멤버별 이동 생성이 적합하지 않다면, 멤버별 이동 할당 역시 적합하지 않을 가능성이 크다. 따라서 이동 생성자와 이동 할당 연산자는 독립적이지 않도록 구현되어 있다.
또한 복사 연산을 하나라도 선언한 클래스에 대해서는 이동 연산들이 작성되지 않는다. 복사 연산을 선언했다는 것은 일반적인 객체 복사 방식이 해당 클래스에 적합하지 않다는 뜻이고, 만일 복사 연산들에 대해 멤버별 복사가 적합하지 않다면 이동 연산들에 대한 멤버별 이동 역시 적합하지 않을 가능성이 크다는 것이다.
반대도 마찬가지다. 이동 연산을 하나라도 명시적으로 선언하면 컴파일러는 복사 연산들을 비활성화 한다. 멤버별 이동이 적절한 객체 이동 방식이 아니라면, 멤버별 복사가 적절한 객체 복사 방식이라고 기대할 수 없다.
3의 법칙(Rule of Three) 라 부르는 지침이 있다. 만일 복사 생성자와 복사 할당 연산자, 소멸자 중 하나라도 선언했다면 나머지 둘도 선언해야 한다는 것이다. 어떤 클래스의 복사 할당 연산을 프로그래머가 직접 작성해야 할 때는 거의 그 클래스가 어떤 형태로든 자원 관리를 수행해야 하기 때문에 발생한다. 이러한 클래스에서는 거의 항상
- 한 복사 연산이 수행하는 자원 관리를 다른 복사 연산에서도 수행해야 하며
- 클래스의 소멸자 역시 그 자원 관리에 참여한다.
결과적으로 클래스에 대한 이동 연산은 다음 세 조건이 모두 만족될 때만, 그리고 필요할 때만 자동으로 작성된다.
- 클래스에 어떤 복사 연산도 선언되어 있지 않다.
- 클래스에 어떤 이동 연산도 선언되어 있지 않다.
- 클래스에 소멸자가 선언되어 있지 않다.
컴파일러가 작성한 함수들의 행동이 정확하다면 C++11에서 기본 행동을 사용하겠다는 의사를 = default를 이용해 명시적으로 표현할 수 있다.
Item 18: Use std::unique_ptr for exclusive-ownership resource management
std::unique_ptr은 raw pointer와 거의 동일한 크기이며, 대부분의 연산들은 raw pointer와 정확히 동일한 명령들을 실행한다.
std::unique_ptr은 독점적 소유권(exclusive ownership) 의미론을 구현하고 있다. std::unique_ptr을 이동하면 소유권이 원본 포인터에서 대상 포인터로 옮겨진다(원본은 null로 설정). std::unique_ptr의 복사는 허용되지 않는다. 따라서 std::unique_ptr은 이동 전용(move-only) 타입이다. null이 아닌 std::unique_ptr은 소멸 시 자신이 가리키는 자원을 파괴한다.
기본적으로 자원 파괴는 delete를 통해 일어나나, 커스텀 삭제자(custom deleter)를 지정할 수도 있다.
auto delInvmt = [](Investment* pInvestment) // custom deleter
{ // (a lambda expression)
makeLogEntry(pInvestment);
delete pInvestment;
};
template<typename... Ts> // revised return type
std::unique_ptr<Investment, decltype(delInvmt)>
makeInvestment(Ts&&... params)
{
// ...
}
std::unique_ptr이 독점 소유권을 표현하는 주된 방법이라는 것 외에, std::shared_ptr로의 변환이 쉽고 효율적인 특징도 있다.
std::shared_ptr<Investment> sp = // converts std::unique_ptr
makeInvestment( arguments ); // to std::shared_ptr
팩토리 함수가 std::unique_ptr을 반환한다면, 호출자에서 좀 더 유연하게 변환할 수 있는 여지가 생긴다.
Item 19: Use std::shared_ptr for shared-ownership resource management
std::shared_ptr을 통해 접근되는 객체의 수명은 그 공유 포인터가 공유된 소유권(shared ownership) 의미론을 통해 관리된다. 객체를 가리키던 마지막 std::shared_ptr이 더 이상 객체를 가리키지 않게 되면, std::shared_ptr은 자신이 가리키는 객체를 파괴한다.
std::shared_ptr은 참조 횟수(reference count)를 통해 최후의 공유 포인터임을 알 수 있다. 참조 횟수는 관리되는 자원에 연관된 값으로, 그 자원을 가리키는 std::shared_ptr들의 개수에 해당한다.
이러한 참조 횟수 관리는 성능에 다음과 같은 영향을 미친다.
std::shared_ptr의 크기는 raw pointer의 두 배이다.- 자원 참조 횟수를 가리키는 raw pointer도 저장해야 하기 때문이다.
- 참조 횟수를 담을 메모리를 반드시 동적으로 할당해야 한다.
std::make_shared를 이용해std::shared_ptr을 생성하면 동적 할당 비용을 피할 수 있다.
- 참조 횟수의 증가와 감소가 반드시 원자적 연산이어야 한다.
참조 횟수가 증가하지 않는 경우는 이동 생성을 사용할 경우이다. 기존의 std::shared_ptr을 이동해 새로우ㄴ std::shared_ptr을 생성하면, 원본 std::shared_ptr은 null이 된다. 즉, 새로운 std::shared_ptr의 수명이 시작되는 시점에 기존 std::shared_ptr은 더 이상 자원을 가리키지 않는 상태가 된다. 따라서 std::shared_ptr을 이동하는 것이 복사하는 것보다 빠르다.
std::shared_ptr은 delete를 기본적인 자원 파괴 메커니즘으로 사용하며, 커스텀 삭제자(custom deleter)를 지원한다. 그러나 지원하는 방식은 std::unique_ptr과는 다르다. std::unique_ptr은 삭제자 타입이 스마트 포인터 타입의 일부였지만, std::shared_ptr은 그렇지 않다. std::shared_ptr의 설계가 더 유연하다.
auto loggingDel = [](Widget *pw) // custom deleter (as in Item 18)
{
makeLogEntry(pw);
delete pw;
};
std::shared_ptr<Widget> // deleter type is not part of ptr type
spw(new Widget, loggingDel);
std::shared_ptr는 객체에 대한 참조 횟수를 가리킨다고 했지만, 사실은 제어 블록(control block) 이라는 자료구조를 가리키고 있다. 커스텀 삭제자를 지정했다면, 참조 횟수와 함께 커스텀 삭제자 복사본이 제어 블록에 담긴다. 커스텀 할당자(custom allocator)를 지정했다면 이 복사본도 제어 블록에 담긴다. 이외에도 약한 참조(weak count)라 부르는 이차적인 참조 횟수가 포함되며 이 밖의 다른 추가 자료도 포함될 수 있다.
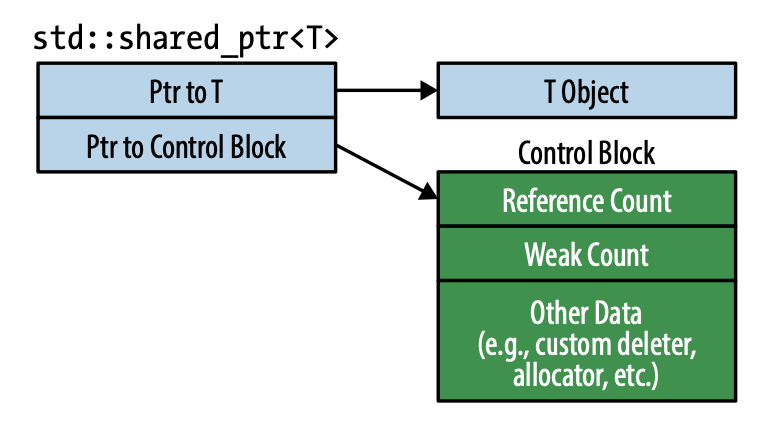
제어 블록은 다음과 같은 규칙들로 생성된다.
std::make_shared는 항상 제어 블록을 생성한다(Item 21).- 고유 소유권 포인터(
std::unique_ptr,std::auto_ptr)로부터std::shared_ptr객체를 생성하면 제어 블록이 생성된다. - raw pointer로
std::shared_ptr생성자를 호출하면 제어 블록이 생성된다.
raw pointer 타입의 변수로부터 std::shared_ptr을 생성하는 일은 피해야 한다. 다음은 *pw에 대해 두 개의 참조 횟수가 있다. 두 참조 횟수는 결국 0이 될 것이며, *pw의 파괴가 두 번 시도되어 의도되지 않은 동작이 발생할 것이다.
auto pw = new Widget; // pw is raw ptr
std::shared_ptr<Widget> spw1(pw, loggingDel); // create control block for *pw
std::shared_ptr<Widget> spw2(pw, loggingDel); // create 2nd control block for *pw!
Item 20: Use std::weak_ptr for std::shared_ptr- like pointers that can dangle
std::shared_ptr처럼 행동하되 가리키는 자원의 소유권 공유에 참여하지 않는 것이 편리한 상황도 있다. 이런 종류의 스마트 포인터는 가리키는 대상이 이미 파괴되었을 수도 있는 문제를 극복해야 한다. 즉, 자신이 가리키는 객체가 더 이상 존재하지 않는 상황을 검출할 수 있어야 한다. std::weak_ptr이 바로 그런 포인터이다.
대체로 std::weak_ptr은 std::shared_ptr을 이용해 생성한다. std::weak_ptr은 자신을 생성하는데 쓰인 std::shared_ptr이 가리키는 것과 동일한 객체를 가리키나, 그 객체의 참조 횟수에는 영향을 주지 않는다.
auto spw = // after spw is constructed,
std::make_shared<Widget>(); // the pointed-to Widget's
// ref count (RC) is 1. (See
// Item 21 for info on
// std::make_shared.)
...
std::weak_ptr<Widget> wpw(spw); // wpw points to same Widget
// as spw. RC remains 1
...
spw = nullptr; // RC goes to 0, and the
// Widget is destroyed.
// wpw now dangles
대상을 잃은 std::weak_ptr을 가리켜 “만료되었다(expired)“라고 한다. 만료 여부는 다음과 같이 확인한다.
if (wpw.expired()) ... // if wpw doesn't point
// to an object...
std::weak_ptr의 만료를 검사해 만료되지 않았다면 객체에 접근하는 방식의 코드를 생각할 수 있다. 하지만 std::weak_ptr은 역참조 연산이 없어 이런 용법은 허용되지 않는다.
제대로 된 용법은 std::weak_ptr의 만료 여부를 점검하고, 아직 만료되지 않았다면 객체에 대한 접근을 돌려주는 연산을 하나의 원자적 연산으로 수행하는 것이다. 즉, std::weak_ptr로부터 std::shared_ptr을 생성하면 되는데, 이 생성 방법은 이미 만료된 std::weak_ptr로 std::shared_ptr을 생성했을 때의 행동 방식에 따라 두 가지로 나뉜다.
-
std::weak_ptr::lock()사용lock()은std::shared_ptr객체를 돌려준다. 만약std::weak_ptr이 만료되었다면 null을 반환한다.std::shared_ptr<Widget> spw1 = wpw.lock(); // if wpw's expired, spw1 is null auto spw2 = wpw.lock(); // same as above, but uses auto -
std::weak_ptr을 인수로 받는std::shared_ptr생성자 사용이 경우
std::weak_ptr이 만료되었다면 예외가 발생한다.std::shared_ptr<Widget> spw3(wpw); // if wpw's expired, // throw std::bad_weak_ptr
Item 21: Prefer std::make_unique and std::make_shared to direct use of new
std::make_shared와 std::make_unique는 임의의 개수와 타입의 인수들을 받아 이것들을 생성자로 완벽 전달해 객체를 동적으로 생성하고, 그 객체를 가리키는 스마트 포인터를 돌려주는 세 가지 make 함수 중 둘이다. 나머지 하나는 std::allocate_shared이다. 이 함수는 std::make_shared처럼 작동하나, 첫 인수가 동적 메모리 할당에 쓰일 할당자 객체이다.
다음과 같은 코드가 있다고 하자.
processWidget(std::shared_ptr<Widget>(new Widget), // potential
computePriority()); // resource
// leak!
processWidget()을 호출할 경우 다음과 같은 일들이 발생한다.
- 표현식
new Widget이 평가된다. 즉,Widget이 힙에 생성된다. new가 산출한 포인터를 관리하는std::shared_ptr<Widget>의 생성자가 실행된다.computePriority()가 실행된다.
그러나 컴파일러가 이 세 가지 작업들을 순서대로 실행하는 코드를 만드는 것은 아니다. std::shared_ptr 생성자가 호출되려면 그 인수가 먼저 평가되어야 하므로, new Widget이 std::shared_ptr보다 먼저 평가된다. 그러나 computePriority()는 이 호출들보다 먼저 실행되거나, 늦게 실행되거나, 혹은 중간에 실행될 수 있다. 따라서 다음과 같은 순서로 실행하는 오브젝트 코드를 산출할 수도 있다.
new Widget실행computePriority()실행std::shared_ptr생성자 실행
만약 computePriority()가 예외를 던지면 1에서 생성된 Widget 객체의 누수(leak)가 발생할 수 있다.
std::make_shared를 사용하면 이와 같은 문제가 생기지 않는다. 위와 동일하게 std::make_shared가 먼저 실행되거나 늦게 실행될 수 있다. 만약 std::make_shared가 먼저라면, 동적으로 할당된 Widget을 가리키는 raw pointer는 computePriority()가 호출되기 전 반환된 std::shared_ptr에 안전하게 저장된다. 그 다음 예외가 발생한다면, std::shared_ptr의 소멸자가 Widget 객체를 파괴한다. computePriority()가 먼저 호출되고 예외를 발생시킨다면, std::make_shared는 아예 호출되지 않아 메모리 누수가 발생될 가능성은 전혀 없다.
또한 std::make_shared를 사용하면 더 간결한 자료구조를 사용하는 작고 빠른 코드를 산출할 수 있게 된다. new를 직접 사용한다면 std::shared_ptr 생성자는 제어 블록을 위한 메모리와 객체를 위한 메모리 할당, 즉 두 번의 할당이 일어난다. std::make_shared를 사용하면 객체와 제어 블록 모두를 담을 수 있는 크기의 메모리 조각을 한 번에 할당한다. 따라서 할당 호출 코드가 한 번만 있으면 되므로 프로그램의 정적 크기가 줄어든다.
make 함수 사용이 불가능 또는 부적합한 다음의 경우들이 있다.
-
make함수들은 커스텀 삭제자를 지정할 수 없다. -
std::initializer_list를 받는 생성자와 받지 않는 생성자를 모두 가진 형식의 객체를 생성할 때, 생성자 인수들을 중괄호로 감싸면 오버로딩 해소 과정에서std::initializer_list를 받는 버전이 선택되고, 괄호로 감싸면std::initializer_list를 받지 않는 버전이 선택된다(Item 7).auto upv = std::make_unique<std::vector<int>>(10, 20); auto spv = std::make_shared<std::vector<int>>(10, 20);위 두 호출 모두 요소의 값이 20인 요소 10개의
std::vector를 생성한다. 중괄호 초기화를 사용하기 위해선 반드시new를 직접 사용해야 한다.make함수로 이와 같은 일을 하려면 중괄호 초기화를 완벽하게 전달해야 하는데, Item 30에서 설명하듯 중괄호 초기화의 완벽 전달은 불가능하다.
std::shared_ptr에 대해서 make 함수가 부적합한 경우가 더 있다.
-
커스텀 메모리 관리 기능을 가진 클래스를 다루는 경우
예를 들어
Widget클래스를 위한operator new와operator delete라면 크기가 정확히sizeof(Widget)인 메모리 조각들의 할당과 해제를 처리하는 데 특화된 경우가 많다. 이런 루틴들은std::shared_ptr의 커스텀 할당(std::allocate_shared를 통한)과 커스텀 해제(커스텀 삭제자를 통한)에 잘 맞지 않는다.std::allocate_shared가 요구하는 메모리 조각의 크기는 객체의 크기가 아니라 그 크기에 제어 블록의 크기를 더한 것이기 때문이다. -
메모리가 넉넉하지 않은 시스템에서 큰 객체를 다루어야 하고
std::weak_ptr들이 해당std::shared_ptr보다 더 오래 살아남는 경우제어 블록에는 여러 관리용 정보가 있는데, 참조 횟수는 제어 블록을 참조하는
std::shared_ptr들의 개수를 뜻한다. 이외에도 제어 블록을 참조하는std::weak_ptr들의 개수에 해당하는 또 다른 참조 횟수도 있다. 이 둘째 참조 횟수를 약한 횟수(weak count) 라 한다. 제어 블록을 참조하는std::weak_ptr들이 존재하는 한 제어 블록을 담고 있는 메모리는 여전히 할당된 상태여야 한다. 따라서std::shared_ptr용make함수가 할당한 메모리 조각은 이것을 참조하는 마지막std::shared_ptr과 마지막std::weak_ptre둘 다 파괴된 후에 해제될 수 있다.
Item 22: When using the Pimpl Idiom, define special member functions in the implementation file
Pimpl 관용구는 클래스의 자료 멤버들을 구현 클래스를 가리키는 포인터로 대체하고, 주 클래스에 쓰이는 멤버들을 그 구현 클래스로 옮기고, 포인터를 통해 간접적으로 접근하는 기법이다. 이 기법은 클래스 구현과 클라이언트 사이 컴파일 의존성을 줄여 빌드 시간을 감소시킨다.
class Widget { // still in header "widget.h"
public:
Widget();
~Widget(); // dtor is needed—see below
...
private:
struct Impl; // declare implementation struct
Impl *pImpl; // and pointer to it
};
#include "widget.h" // in impl. file "widget.cpp"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // definition of Widget::Impl
std::string name; // with data members formerly
std::vector<double> data; // in Widget
Gadget g1, g2, g3;
};
Widget::Widget() // allocate data members for
: pImpl(new Impl) // this Widget object
{}
Widget::~Widget() // destroy data members for
{ delete pImpl; } // this object
선언만 하고 정의는 하지 않는 타입을 불완전 타입(incomplete type)이라 부른다. 여기서는
Widget::Impl이 이런 타입이다.
std::unique_ptr(Item 18)을 통해 raw pointer를 대체해보자.
class Widget { // in "widget.h"
public:
Widget();
...
struct Impl;
std::unique_ptr<Impl> pImpl; // use smart pointer instead of raw pointer
};
#include "widget.h" // in "widget.cpp"
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl { // as before
// ...
};
Widget::Widget() // per Item 21, create
: pImpl(std::make_unique<Impl>()) // std::unique_ptr
{} // via std::make_unique
위 코드 자체는 컴파일되나, 이를 사용하는 클라이언트 쪽에서는 컴파일 되지 않는다.
#include "widget.h"
Widget w; // error!
w가 파괴되는 지점에서 w의 소멸자가 호출되는데, std::unique_ptr을 이용하는 Widget 클래스에는 따로 소멸자가 선언되어 있지 않다(소멸자에서 해야 할 일이 없음). 이 경우 컴파일러가 생성하는 특수 멤버 함수에 대한 통상적인 규칙들에 의해 컴파일러가 대신 소멸자를 작성해준다. 이 소멸자 안에 Widget의 자료 멤버 pImpl의 소멸자를 호출하는 코드를 삽입한다. 즉, 기본 삭제자를 사용하는 std::unique_ptr이고, 그 기본 삭제자는 std::unique_ptr 안에 있는 raw pointer에 대해 delete를 적용하는 함수이다. 그런데 대부분의 삭제자 함수는 delete를 적용하기 전, raw pointer가 불완전한 형식을 가리키지는 않는지 static_assert를 이용해 점검한다. 컴파일러는 Widget 객체 w의 파괴를 위한 코드를 산출하는 과정에서 static_assert는 참이 아닌 것으로 판정되며, 오류가 발생하게 된다.
std::unique_ptr<Widget::Impl>을 파괴하는 코드가 만들어지는 지점에서 Widget::Impl이 완전한 형식이 되게 하면 문제는 해결된다. 컴파일러는 형식의 정의를 보게 되면 그 형식을 완전한 형식으로 간주한다. 그리고 Widget::Impl의 정의는 widget.cpp에 있다. 따라서 Wdiget::Impl 정의 이후에 컴파일러가 그 소스 파일에 있는 Widget의 소멸자의 본문(즉, 컴파일러가 std::unique_ptr 자료 멤버를 파괴하는 코드를 작성하는 곳)을 보게 한다면 클라이언트 코드는 문제없이 컴파일된다.
class Widget { // as before, in "widget.h"
public:
Widget();
~Widget(); // declaration only
...
private: // as before
struct Impl;
std::unique_ptr<Impl> pImpl;
};
Widget::~Widget() = default; // same effect as above
객체 내부 pImpl 포인터가 구현 객체를 독점적으로 소유한다는 점에서, Pimpl 관용구에 적합한 스마트 포인터는 std::unique_ptr이다.
Rvalue References, Move Semantics, and Perfect Forwarding
-
이동 의미론(move semantics)
컴파일러는 비싼 복사 연산 대신 덜 비싼 이동 연산으로 대체할 수 있다.
-
완벽 전달(perfect forwarding)
임의의 인수를 받아 이것들을 다른 함수로 전달하는 함수를 작성할 때, 그 대상 함수가 애초에 전달 함수가 받은 것과 정확히 같은 인수들을 받게 만들 수 있다.
Item 23: Understand std::move and std::forward
std::move와 std::forward는 그냥 캐스팅을 수행하는 함수다. std::move는 주어진 인수를 무조건 오른값으로 캐스팅하고, std::forward는 특정 조건이 만족될 때마다 이런 캐스팅을 수행한다.
template<typename T> // C++14; still in
decltype(auto) move(T&& param) { // namespace std
using ReturnType = remove_reference_t<T>&&;
return static_cast<ReturnType>(param);
}
std::move는 객체에 대한 참조(universal reference: Item 24)를 받아 같은 객체에 대한 어떤 참조를 돌려준다.
함수의 반환 타입에 있는 &&은 하나의 오른값 참조를 돌려준다. 그러나 타입 T가 왼값 참조면 T&&는 왼값 참조가 된다. 이를 방지하기 위해 T에 std::remove_reference_t를 적용한다. 그러면 반환 타입의 &&은 항상 참조가 아닌 타입에 적용된다. 즉, std::move는 반드시 오른값 참조를 돌려준다.
text를 자료 멤버에 복사할 때 복사 연산 비용을 치르지 않고, std::move를 text에 적용해 오른값을 얻는다고 하자(Item 41).
class Annotation {
public:
explicit Annotation(const std::string text)
: value(std::move(text)) // "move" text into value; this code
{ ... } // doesn't do what it seems to!
...
private:
std::string value;
};
text는 value로 이동하는 것이 아닌 복사가 된다. std::move 때문에 text가 오른값으로 캐스팅되지만, text는 const std::string으로 선언되어 캐스팅 이전에 왼값 const std::string이고, 캐스팅 결과는 오른값 const std::string이다. 즉, const가 그대로 유지된다.
컴파일러가 std::string 생성자 중 하나를 선택할 때 const의 존재가 어떤 영향을 미치는지 보자.
class string { // std::string is actually a
public: // typedef for std::basic_string<char>
...
string(const string& rhs); // copy ctor
string(string&& rhs); // move ctor
...
};
std::move(text)의 결과는 const std::string 타입의 오른값이다. 이 오른값은 std::string의 이동 생성자에 전달할 수 없다. 왜냐하면, 이 이동 생성자는 const가 아닌 std::string에 대한 오른값 참조를 받기 때문이다. 그러나 const std::string을 복사 생성자에 전달할 수는 있다. 따라서 std::string의 복사 생성자를 호출한다.
여기서 배울 점은 두 가지이다.
- 이동을 지원할 객체는
const로 선언하지 말아야 한다. std::move는 실제 아무것도 이동하지 않으며, 캐스팅되는 객체가 이동 자격을 갖추게 된다는 보장도 제공하지 않는다. 확실한 것은std::move를 적용한 결과가 하나의 오른값이라는 것 뿐이다.
std::forward에 대해서도 std::move와 비슷하게 적용된다. 단, std::move는 주어진 인수를 무조건 오른값으로 캐스팅하지만, std::forward는 특정 조건이 만족될 때만 캐스팅한다. 즉, 조건부 캐스팅이다.
Universal reference 매개변수를 받아 이것을 다른 어떤 함수에 전달하는 함수를 보자.
void process(const Widget& lvalArg); // process lvalues
void process(Widget&& rvalArg); // process rvalues
template<typename T> // template that passes
void logAndProcess(T&& param) { // param to process
auto now =
std::chrono::system_clock::now(); // get current time
makeLogEntry("Calling 'process'", now);
process(std::forward<T>(param));
}
Widget w;
logAndProcess(w); // call with lvalue
logAndProcess(std::move(w)); // call with rvalue
logAndProcess()는 param을 함수 process()에 전달한다. 따라서 logAndProcess() 내부에서 일어나는 모든 process() 호출은 결국 process()의 왼값 오버로딩 버전을 실행하게 된다(logAndProcess()에 전달된 인수 자체는 왼값이므로). 이를 방지하기 위해 param을 초기화하는 데 쓰인 인수가 오른값이면, 이럴 때만 param을 오른값으로 캐스팅하는 메커니즘이 필요하다. std::forward가 하는 일이 바로 이것이다. 주어진 인수가 오른값으로 초기화된 것일 때만 이것을 오른값으로 캐스팅한다는 점에서 조건부 캐스팅이라 한다.
std::move는 주어진 인수를 무조건 오른값으로 캐스팅하겠다는 뜻이지만, std::forward는 오른값에 묶인 참조만 오른값으로 캐스팅하겠다는 뜻이다. 후자는 객체의 왼값 또는 오른값 성질을 유지한 채로 다른 함수에 넘겨주는, 즉 전달하는(forward) 것이다.
Item 24: Distinguish universal references from rvalue references
어떤 타입 T에 대해 오른값 참조를 선언할 때는 T&& 표기를 사용한다. 따라서 T&&를 발견한다면 이것이 오른값 참조라 가정할 수 있지만, 그렇게 단순하지 않다.
T&&에는 두 가지 의미가 있다.
- 오른값 참조
- 오직 오른값에만 묶이며, 일차적인 존재 이유는 이동의 원본이 될 수 있는 객체를 지정하는 것
- 오른값 참조 또는 왼값 참조 중 하나
- 소스 코드에서는 오른값 참조(
T&&)로 보이나, 때에 따라서는 왼값 참조(T&)인 것처럼 행동한다. 따라서 이런 참조는 오른값 또는 왼값으로 묶일 수 있다. - 더욱이 이런 참조는
const객체에 묶을 수도 있고,non-const객체도 묶을 수 있으며,volatile객체에 묶을 수도 있고non-volatile객체에도 묶을 수 있다. - 즉, 거의 모든 것에 묶을 수 있다 하여 보편 참조(universal reference) 라 한다.
- 소스 코드에서는 오른값 참조(
보편 참조는 두 가지 문맥에서 나타난다.
-
템플릿 매개변수
template<typename T> void f(T&& param); // param is a universal reference -
auto선언auto&& var2 = var1; // var2 is a universal reference
이 두 문맥의 경우 타입 추론이 일어난다. 템플릿 f()에서는 param의 타입 추론이 되고, var2의 선언에서는 var2의 타입이 추론된다. 타입 추론이 일어나지 않는 경우 T&&가 있다면 이는 오른값 참조이다.
void f(Widget&& param); // no type deduction;
// param is an rvalue reference
Widget&& var1 = Widget(); // no type deduction;
// var1 is an rvalue reference
보편 참조는 참조이므로 반드시 초기화해야 한다. 보편 참조가 오른값 참조를 나타내는지 왼값 참조를 나타내는지는 보편 참조의 초기치(initializer)가 결정한다. 초기치가 왼값이면 보편 참조는 왼값 참조에 해당한다. 보편 참조가 함수의 매개변수인 경우, 초기치는 이 함수를 호출하는 지점에서 제공한다.
Widget w; // lvalue passed to f; param's type is
f(w); // Widget& (i.e., an lvalue reference)
f(std::move(w)); // rvalue passed to f; param's type is
// Widget&& (i.e., an rvalue reference)
Item 25: Use std::move on rvalue references, std::forward on universal references
오른값 참조는 이동할 수 있는 객체에만 바인딩된다. 어떤 매개변수가 오른값 참조라면, 그 참조에 바인딩된 객체를 이동할 수 있다.
반면 보편 참조는 이동에 적합한 객체 바인딩될 수도 있고 아닐 수도 있다. 보편 참조는 오른값으로 초기화되는 경우에만 오른값으로 캐스팅되어야 한다(std::forward).
즉, 오른값 참조를 다른 함수로 전달할 때는 오른값으로의 무조건적인 캐스팅(std::move)을 적용하고, 보편 참조를 다른 함수로 전달할 때는 오른값으로의 조건부 캐스팅을 적용해야 한다(std::forward).
오른값 참조에 std::forward를 사용해도 원하는 동작이 수행되나, 코드가 길어지고 실수의 여지가 있으며 관용구에 벗어난 모습이 된다. 따라서 오른값 참조에 std::forward를 사용하는 것은 피해야 한다.
보편 참조에 std::move를 적용하는 것은 더 좋지 않다. 이렇게 되면 왼값(지역변수 등)이 의도치 않게 수정되는 결과가 일어날 수 있다.
class Widget {
public:
template<typename T>
void setName(T&& newName) // universal reference compiles, but is
{ name = std::move(newName); } // bad, bad, bad!
...
private:
std::string name;
std::shared_ptr<SomeDataStructure> p;
};
std::string getWidgetName(); // factory function
Widget w;
auto n = getWidgetName(); // n is local variable
w.setName(n); // moves n into w!
... // n's value now unknown
다음과 같이 ‘복사’를 ‘이동’으로 바꾸어 함수를 최적화할 수 있다고 생각할 수 있다.
Widget makeWidget() // Moving version of makeWidget
{
Widget w;
...
return std::move(w); // move w into return value (don't do this!)
}
그러나 여기서 간과한 것은 이런 종류의 최적화를 위한 대비책이 이미 마련되어 있다는 것이다. 지역변수 w를 함수의 반환값을 위해 마련한 메모리 안에 생성한다면 w의 복사를 피할 수 있다. 이를 반환값 최적화(RVO: Return Value Optimization) 이라 한다.
컴파일러가 결과를 값 전달 방식으로 반환하는 함수의 어떤 지역 객체의 복사를 제거할 수 있으려면
- 그 지역 객체의 타입이 함수의 반환 타입과 같아야 하고
- 그 지역 객체가 함수의 반환값이어야 한다.
Widget makeWidget() // "Copying" version of makeWidget
{
Widget w;
...
return w; // "copy" w into return value
}
따라서 위 예에서는 조건이 모두 만족되므로 반환값 최적화를 적용해 w의 복사를 피할 것이다.
하지만 std::move(w)를 적용한 버전은 반환값은 지역 객체 w가 아닌 w에 대한 참조이다. 따라서 RVO의 조건을 만족하지 못하며, 컴파일러는 반드시 w를 함수의 반환값 장소로 옮겨야 한다. 결과적으로 std::move를 통해 최적화하려 했으나, 실제로는 컴파일러가 할 수 있는 최적화를 제한하게 된다.
Item 26: Avoid overloading on universal references
오버로딩된 logAndAdd()가 있고,
std::string nameFromIdx(int idx); // return name corresponding to idx
void logAndAdd(int idx) // new overload
{
auto now = std::chrono::system_clock::now();
log(now, "logAndAdd");
names.emplace(nameFromIdx(idx));
}
template<typename T> void logAndAdd(T&& name) {
auto now = std::chrono::system_clock::now();
log(now, "logAndAdd");
names.emplace(std::forward<T>(name));
}
클라이언트가 인덱스 값을 담은 short를 전달한다고 하자.
short nameIdx;
... // give nameIdx a value
logAndAdd(nameIdx); // error!
보편 참조를 받는 버전은 T를 short&로 추론할 수 있으며, 이러면 주어진 인수와 정확히 부합되는 형태가 되어 보편 참조 오버로딩이 호출된다. 보편 참조를 받는 오버로딩에서 name은 주어진 short에 바인딩된다. 그 다음 name이 std::forward를 통해 names의 멤버 함수 emplace()에 전달된다. emplace()는 이를 std::string 생성자에 전달한다. 그런데 std::string 생성자 중 short를 받는 버전은 없으므로 컴파일이 실패한다.
보편 참조를 받는 템플릿 함수는 C++에서 가장 욕심 많은 함수다. 이런 템플릿 인스턴스는 거의 모든 타입의 인수와 정확히 부합한다. 보편 참조 오버로딩이 예상한 것보다 훨씬 많은 인수 타입들을 받아들인다는 점에서 오버로딩과 결합하는 것은 거의 항상 나쁜 선택이다.
완벽 전달(perfect forward) 생성자를 사용해 해결할 수 있겠지만 문제는 더 심각해진다. std::string을 받는 Person 클래스를 만들어보자.
class Person {
public:
template<typename T>
explicit Person(T&& n) // perfect forwarding ctor; initializes data member
: name(std::forward<T>(n)) {}
explicit Person(int idx) // int ctor
: name(nameFromIdx(idx)) {}
...
private:
std::string name;
};
int 이외의 정수 타입을 넘겨주면 int를 받는 생성자 대신 보편 참조를 받는 생성자가 호출되어 컴파일에 실패한다. C++은 특정 조건에서 복사 생성자와 이동 생성자를 자동으로 작성하며, 심지어 템플릿화된 생성자가 복사 생성자나 이동 생성자에 해당하는 서명으로 인스턴스화되는 경우에도 자동으로 만들어진다. 따라서 Person에 대해 복사 생성자와 이동 생성자가 작성된다면 다음과 같을 것이다.
class Person {
public:
template<typename T> // perfect forwarding ctor
explicit Person(T&& n)
: name(std::forward<T>(n)) {}
explicit Person(int idx); // int ctor
Person(const Person& rhs); // copy ctor (compiler-generated)
Person(Person&& rhs); // move ctor (compiler-generated)
...
};
따라서 다음과 같은 코드는 이상하게 동작할 것이다.
Person p("Nancy");
auto cloneOfP(p); // create new Person from p;
// this won't compile!
이 코드는 완벽 전달 생성자가 호출한다. 이 함수는 Person의 std::string 자료 멤버를 Person 객체(p)로 생성하려 하는데, std::string은 Person을 받는 생성자가 없으므로 컴파일이 실패한다.
복사할 객체를 const로 바꾸면 상황이 달라진다.
const Person cp("Nancy"); // object is now const
auto cloneOfP(cp); // calls copy constructor!
이제 복사 생성자와 정확히 부합된다.
C++의 오버로딩 해소 규칙에 어떤 함수 호출이 템플릿 인스턴스와 비템플릿 인스턴스(보통 함수)에 똑같이 부합한다면, 보통 함수를 우선시하는 규칙이 있기 때문이다. 그래서 복사 생성자가 자신과 같은 서명을 가진 템플릿 인스턴스보다 우선시된다.
상속에 관여하는 클래스에서는 완벽 전달 생성자와 컴파일러가 작성한 복사 및 이동 연산들 사이 상호작용히 미치는 여파가 더욱 커진다. 파생 클래스의 복사, 이동 생성자는 해당 기반 클래스의 복사, 이동 생성자를 호출하는 것이 아니라, 기반 클래스의 완벽 전달 생성자를 호출한다.
class SpecialPerson: public Person {
public:
SpecialPerson(const SpecialPerson& rhs) // copy ctor; calls
: Person(rhs) // base class
{ ... } // forwarding ctor!
SpecialPerson(SpecialPerson&& rhs) // move ctor; calls
: Person(std::move(rhs)) // base class
{ ... } // forwarding ctor!
};
완벽 전달 생성자는 대체로 non-const 왼값에 대한 복사 생성자보다 더 나은 부합이며, 기반 클래스 복사 및 이동 생성자들에 대한 파생 클래스의 호출들을 가로챌 수 있기 때문이다.
Item 27: Familiarize yourself with alternatives to overloading on universal references
보편 참조에 대한 오버로딩이 아닌 기법을 이용해, 또는 보편 참조에 대한 오버로딩이 부합할 수 있는 인수들의 타입을 제한하여 이런 바람직한 행동을 달성하는 방법들을 보자.
-
Abandon overloading
오버로딩 버전에 각자 다른 이름을 붙이면 보편 참조에 대한 오버로딩에 대한 단점을 피할 수 있다(Item 26). 그러나 생성자 오버로딩에서 문제가 발생될 수 있다.
-
Pass by const T&
보편 참조 대신
const에 대한 왼값 참조 매개변수를 사용하는 것이다(Item 26). 그러나 보편 참조와 오버로딩의 상호 작용에 의한 문제점이 있으니 효율성을 포기하더라도 예상치 않은 문제를 피하는 것이 좋다. -
Pass by value
복잡도를 높이지 않고 성능을 높일 수 있는 한 가지 방식으로, 참조 전달 매개변수 대신 값 전달 매개변수를 사용하는 것이다.
class Person { public: explicit Person(std::string n) // replaces T&& ctor; see : name(std::move(n)) {} // Item 41 for use of std::move explicit Person(int idx) // as before : name(nameFromIdx(idx)) {} ... private: std::string name; }; -
Use Tag dispatch 보편 참조를 사용하려는 이유가 완벽 전달이라면, 보편 참조 말고는 다른 대안이 없다. 이 경우에도 보편 참조와 오버로딩 둘 다 사용하되 보편 참조에 대한 오버로딩을 피하려면 태그 디스패치(tag dispatch) 를 사용하면 된다.
매개변수 목록에 보편 참조 매개변수 뿐 아니라 보편 참조가 아닌 매개변수들도 포한되어 있으면, 보편 참조 매개변수가 있는 오버로딩을 제치고 선택될 가능성이 있다. 이것이 태그 디스패치 접근 방식이다.
실제 작업을 수행하는 두 함수의 이름을
logAndAddImpl()로 한다. 즉, 이들에 대해서 오버로딩을 수행한다. 둘 중 하나는 보편 참조를 받는다. 두 함수는 전달된 인수가 정수 타입인지 아닌지를 뜻하는 매개변수를 받는다.template<typename T> void logAndAdd(T&& name) { logAndAddImpl(std::forward<T>(name), std::is_integral<T>()); // not quite correct }이 함수는 자신의 매개변수를
logAndAddImpl()에 전달하며, 이와 함께 매개변수 타입T가 정수인지를 뜻하는 인수도 전달한다. 만약name으로 전달된 인수가 왼값이면T는 왼값 참조 타입으로 추론(Item 28)된다. 따라서int타입의 왼값이logAndAdd()에 전달되면,T는int&로 추론된다. 참조는 정수 타입이 아니므로std::is_integral<T>는 거짓이 된다.이를 해결하기 위해
std::remove_reference를 사용한다.template<typename T> void logAndAdd(T&& name) { logAndAddImpl( std::forward<T>(name), std::is_integral<typename std::remove_reference<T>::type>() ); }std::true_type타입과std::false_type타입은 오버로딩 해소에 우리가 원하는 방식으로 일어나게 하는 데에 쓰이는 일종의 “태그(tag)“이다. -
Constraining templates that take universal references
완벽 전달 생성자에 대한 문제는 태그 디스패처로는 해결할 수 없다. 컴파일러가 자동으로 복사 생성자와 이동 생성자를 작성하기 때문에, 생성자 하나만 작성해 그 안에서 태그 디스패치를 사용한다면 일부 생성자 호출은 컴파일러가 작성한 함수들로 처리되어 태그 디스패치가 적용되지 않을 위험이 있다.
std::enable_if를 이용하면 컴파일러가 마치 특정 템플릿이 존재하지 않는 것처럼 행동할 수 있다. 이런 템플릿을 비활성화된(disabled) 템플릿이라 한다.Person예에서는Person이 아닌 타입의 인수가 전달된 경우에만Person의 완벽 전달 생성자가 활성화되게 해야 한다.class Person { public: template<typename T, typename = typename std::enable_if<condition>::type> explicit Person(T&& n); ... };두 타입이 같은지를 확인하는
std::is_same이 있다. 이를 이용해!std::is_same<Person, T>::value표현식을 조건으로 지정하면 되겠다. 그러나 왼값으로 초기화되는 보편 참조는 항상 왼값 참조로 추론된다. 즉,Person&로 추론되어std::is_same은 다르다고 판정할 것이다.그렇다면
T에 대해 다음 두 사항을 무시해야 할 것이다.- 참조 여부
const성과volatile성
표준 라이브러리에는
std::decay라는 특질(trait)이 있다.std::decay<T>::type은T에서 모든 참조와 cv-한정사(cv-qualifier:const,volatilequalifier)를 제거한 타입에 해당한다. 결과적으로 다음과 같은 코드가 될 것이다.class Person { public: template< typename T, typename = typename std::enable_if< !std::is_same<Person, typename std::decay<T>::type >::value >::type > explicit Person(T&& n); ... };그러나 아직
Person에서 파생된 클래스에서 문제가 발생될 수 있다.SpecialPerson객체가 복사 연산들과 이동 연산들을 통상적인 방식으로 구현했다고 하자(Item 26).복사, 이동 생성자들은
SpecialPerson객체를 기반 클래스의 생성자들에 넘겨주는데,SpecialPerson은Person과 같지 않으므로(std::decay적용 후에도) 기반 클래스의 보편 참조 생성자 템플릿이 활성화된다.특정 타입에서 파생된 것인지를 알려주는
std::is_base_of특질이 있다.std::is_base_of<T1, T2>::value는 만일 T2가 T1에서 파생된 타입이면 참이게 된다. 따라서std::is_same만std::is_base_of로 바꾸면 된다. C++14 버전으로 더 간결한 코드를 만들 수 있다.class Person { // C++14 public: template< typename T, typename = std::enable_if_t< // less code here !std::is_base_of<Person, std::decay_t<T> // and here >::value > // and here > explicit Person(T&& n); ... };이제 마지막으로 다음 두 가지만 하면 된다.
- 정수 인수들을 처리하는
Person생성자 오버로딩 추가 - 이런 인수들에 대해서는 템플릿화된 생성자가 비활성화되도록 하는 조건 추가
class Person { public: template< typename T, typename = std::enable_if_t< !std::is_base_of<Person, std::decay_t<T>>::value && std::is_integral<std::remove_reference_t<T>>::value > > explicit Person(T&& n) // ctor for std::strings and : name(std::forward<T>(n)) // args convertible to { ... } // std::strings explicit Person(int idx) // ctor for integral args : name(nameFromIdx(idx)) { ... } ... // copy and move ctors, etc. private: std::string name; }; -
Trade-offs
처음의 세 가지 기법은 호출되는 함수들의 각 매개변수 타입을 지정한다.
- 오버로딩을 피하는 것
const T&를 전달하는 것- 값을 전달하는 것
나머지 두 기법은 완벽 전달을 사용하므로, 매개변수 타입을 지정하지 않는다.
- 태그 디스패치
- 템플릿 활성화 제한
완벽 전달이 더 효율적이나 단점들이 있다. 완벽 전달이 불가능한 인수들이 있다는 점과 클라이언트가 유효하지 않은 인수를 전달했을 때 오류 메시지가 난해하다는 것이다.
Person의 경우 보편 참조 매개변수가std::string에 대한 초기화로 쓰일 것을 알고 있으므로, 이 초기화로 사용하는 것이 가능하지 미리static_assert를 통해 점검하는 방법도 있다.std::is_constructible특질은 한 타입의 객체를 다른 한 타입의 객체로부터 생성할 수 있는지를 컴파일 타임에 판정할 수 있다.static_assert( std::is_constructible<std::string, T>::value, "Parameter n can't be used to construct a std::string" );
Item 28: Understand reference collapsing
템플릿 매개변수 T에 대해 추론된 타입을 param으로 전달된 인수가 왼값이었는지 오른값이었는지에 대한 정보가 인코딩될 것이다.
template<typename T>
void func(T&& param);
C++에서 참조에 대한 참조는 위법이다.
int x;
auto& & rx = x; // error! can't declare reference to reference
그런데 보편 참조를 받는 함수 템플릿에 왼값을 넘겨주면 T에 대해 추론된 타입(Widget &)으로 템플릿이 인스턴스화한 결과는 다음과 같다.
void func(Widget& && param);
이는 참조에 대한 참조지만 컴파일된다. 보편 참조 param은 왼값으로 초기화되므로, param 타입은 왼값 참조가 된다. 따라서 컴파일러가 T에 대해 추론된 타입을 템플릿에 대입하면 위와 같은 시그니처가 나온다. 그러나 실제로 만들어지는 시그니처는 다음과 같다.
void func(Widget& param);
이는 참조 축약(reference collapsing) 이다. 참조에 대한 참조는 위법이나, 특정 문맥에서 컴파일러가 참조에 대한 참조를 산출하는 것이 허용된다. 템플릿 인스턴스화가 이런 문맥 중 하나이다.
참조는 두 종류(왼값, 오른값)로 참조에 대한 참조가 가능한 조합은 총 네 가지이다.
만일 두 참조 중 하나라도 왼값이면 결과는 왼값 참조이다. 그렇지 않으면(둘 다 오른값 참조) 결과는 오른값 참조이다.
std::forward가 작동하는 것은 이 참조 축약 덕분이다. Item 25에서 설명하듯 std::forward는 보편 참조 매개변수에 적용된다.
template<typename T>
void f(T&& fParam)
{
... // do some work
someFunc(std::forward<T>(fParam)); // forward fParam to someFunc
}
fPararm이 보편 참조이므로 f()에 전달된 인수가 왼값인지 오른값인지에 대한 정보가 타입 매개변수 T에 인코딩된다.
다음은 std::forward의 가능한 구현 중 하나이다.
template<typename T> // in namespace std
T&& forward(typename
remove_reference<T>::type& param)
{
return static_cast<T&&>(param);
}
f()에 전달된 인수가 Widget 타입의 왼값이라고 하자. 그러면 T는 Widget&로 추론되며 std::forward<Widget&> 타입으로 인스턴스화된다. Widget&를 std::forward의 구현에 대입하면 다음과 같아질 것이다.
Widget& && forward(typename
remove_reference<Widget&>::type& param)
{ return static_cast<Widget& &&>(param); }
remove_reference<Widget&>::type는 Widget을 산출하므로 std::forward는 다음과 같이 변한다.
Widget& && forward(Widget& param)
{ return static_cast<Widget& &&>(param); }
참조 축약이 적용된 최종 버전은 다음과 같다.
Widget& forward(Widget& param) // still in
{ return static_cast<Widget&>(param); } // namespace std
만약 f()에 전달된 인수가 Widget 타입의 오른값이면 f() 타입 매개변수 T에 대해 추론되는 타입은 그냥 Widget이다.
Widget&& forward(typename
remove_reference<Widget>::type& param)
{ return static_cast<Widget&&>(param); }
remove_reference를 비참조 타입 Widget에 적용하면 Widget이 산출되므로 std::forward는 다음과 같아진다.
Widget&& forward(Widget& param)
{ return static_cast<Widget&&>(param); }
여기서 참조 축약이 일어난 문맥은 네 가지이다.
- 템플릿 인스턴스화
auto변수에 대한 타입 추론typedef와 별칭 선언의 지정 및 사용(Item 9)decltype사용
Item 29: Assume that move operations are not present, not cheap, and not used
다음은 C++에서 이동 의미론이 도움이 되지 않는 몇 가지 시나리오다.
- 이동 연산이 없다. 이동할 객체가 이동 연산들을 제공하지 않는다. 이 경우 이동 요청은 복사 요청이 된다.
- 이동이 더 빠르지 않다. 이동할 객체의 이동 연산이 해당 복사 연산보다 빠르지 않다.
- 이동을 사용할 수 없다. 이동이 일어나려면 이동 연산이 예외를 방출하지 않아야 하는 문맥에서, 해당 연산이 noexcept로 선언되어 있지 않다.
다음은 이동 의미론이 효율성 면에서 이득이 되지 않는 시나리오다.
- 원본 객체가 왼값이다. 드문 경우(Item 25)지만, 오직 오른값만 이동 연산의 원본이 될 수 있는 경우도 있다.
Item 30: Familiarize yourself with perfect forwarding failure cases
전달(forwarding)은 한 함수가 자신들의 인수들을 다른 함수에 넘겨주는 것을 뜻한다. 이때 목표는 둘째 함수(전달받는 함수)가 첫 함수(전달하는 함수)가 받았던 것과 동일한 객체들을 받게 하는 것이다. 값 전달 방식의 매개변수로는 이런 목표를 달성할 수 없다. 원래의 호출자가 넘겨준 인수의 복사본이기 때문이다. 우리가 원하는 것은 전달받는 함수가 원래 전달된 객체를 다룰 수 있게 하는 것이다.
완벽 전달은 단순히 객체들을 전달하는 것만이 아니라, 그 객체들의 타입, 왼값, 오른값 여부, const나 volatile 여부까지 전달하는 것이다. 이를 위해선 보편 참조 매개변수(Item 24)가 필요하다.
template<typename... Ts>
void fwd(Ts&&... params) // accept any arguments
{
f(std::forward<Ts>(params)...); // forward them to f
}
대상 함수 f()와 전달 함수 fwd()가 있다고 할 때, 만약 어떤 인수로 f()을 호출했을 때 일어나는 일과 같은 인수로 fwd()를 호출했을 때 일어나는 일이 다르다면 완벽 전달은 실패한 것이다.
이러한 실패 사례들을 살펴보자.
-
Braced initializers
f()의 선언이 다음과 같다고 할 때,void f(const std::vector<int>& v);중괄호 초기화(
fwd())에 넘겨주는 코드는 컴파일되지 않는다.fwd({ 1, 2, 3 }); // error! doesn't compile템플릿
fwd()를 통해f()를 간접적으로 호출할 때, 컴파일러는fwd()의 호출 지점에서 전달된 인수들과f()에 선언된 매개변수를 직접 비교할 수 없다. 대신 컴파일러는fwd()에 전달되는 인수들의 타입을 추론하고, 추론된 타입들을f()의 매개변수 선언들과 비교한다. 이때 다음 두 조건 중 하나라도 만족하면 완벽 전달은 실패한다.fwd()의 매개변수들 중 하나 이상에 대해 컴파일러가 타입을 추론하지 못한다.fwd()의 매개변수들 중 하나 이상에 대해 컴파일러가 타입을 잘못 추론한다.
fwd({ 1, 2, 3 })호출에서는std::initializer_list가 될 수 없는 타입으로 선언된 함수 템플릿 매개변수에 중괄호 초기화로 넘겨준다는 것이다. 이를 비추론 문맥(non-deduced context) 이라 한다. 즉,fwd()의 매개변수가std::initializer_list가 될 수 없는 타입으로 선언되어 있어fwd()에 쓰인 표현식{ 1, 2, 3 }의 타입을 컴파일러가 추론하는 것이 금지되어 있다는 뜻이다. -
0 or NULL as null pointers
0이나
NULL을 템플릿에 넘겨주려 하면 컴파일러는 이를 포인터 타입이 아닌 정수 타입으로 추론한다(Item 8). 해결책으로nullptr을 사용하면 된다. -
Declaration-only integral static const and constexpr data members
static const멤버와static constexpr멤버는 클래스 안에서 정의할 필요가 없다. 선언만 하면 된다. 이런 멤버의 값에 대해 컴파일러는 const 전파(const propagation) 를 적용해, 이런 멤버의 값을 위한 메모리를 따로 마련할 필요가 없어지기 때문이다.class Widget { public: static const std::size_t MinVals = 28; // MinVals' declaration ... }; ... // no defn. for MinValsfwd(Widget::MinVals)를 호출하면 링크에 실패한다. 코드에MinVals의 주소를 취하는 부분이 없다 해도,fwd()매개변수는 보편 참조이며 컴파일러가 산출한 코드에서 참조는 포인터처럼 취급되는 것이 보통이다. 따라서MinVals를 참조로 전달하는 것은 사실상 포인터로 넘겨주는 것이며, 이런 포인터가 가리킬 뭔가가 필요하다. 따라서static const멤버와static constexpr멤버를 참조로 전달하려면 이 멤버를 정의할 필요가 있다.const std::size_t Widget::MinVals; // in Widget's .cpp file -
Overloaded function names and template names
f()가 다음과 같이 함수 포인터를 받고,void f(int pf(int));오버로딩된
processVal()함수가 있다고 하자.int processVal(int value); int processVal(int value, int priority);함수 템플릿
fwd(processVal)은 이러한 호출에 필요한 타입에 대한 정보가 전혀 없다. 따라서 컴파일러는 어떤 오버로딩을 선택해야 할지 결정하지 못한다.함수 템플릿을 사용하려 할 때도 같은 문제가 발생한다. 함수 템플릿은 하나의 함수를 나타내는 것이 아니라 다수의 함수를 대표한다.
template<typename T> T workOnVal(T param) // template for processing values { ... } fwd(workOnVal); // error! which workOnVal instantiation?fwd()같은 완벽 전달 함수가 오버로딩된 함수 이름이나 템플릿 이름을 받아들이게 하려면, 전달하고자 하는 오버로딩이나 템플릿 인스턴스를 명시적으로 지정하면 된다.using ProcessFuncType = int (*)(int) // make typedef; see Item 9 ProcessFuncType processValPtr = processVal; // specify needed signature for processVal fwd(processValPtr); // fine fwd(static_cast<ProcessFuncType>(workOnVal)); // also fine -
Bitfields
비트필드가 함수 인수로 쓰일 때 완벽 전달이 실패한다. 임의의 비트들을 가리키는 포인터를 생성하는 방법은 없으며, 따라서 참조를 임의의 비트들에 묶는 방법도 없다.
그러나 우회책을 사용해 비트필드의 완벽 전달을 가능하게 할 수 있다. 전달 대상 함수가 항상 비트필드 값의 복사본을 받게 되는 사실을 활용하는 것이다.
-
값으로 전달
호출될 함수가 비트필드 값의 복사본임이 명확하다.
-
const에 대한 참조로 전달const참조는 비트필드 자체에 바인딩되는 것이 아니라 복사된 ‘보통’ 객체에 바인딩된다.
-
Lambda Expressions
- 클로저(closure) 는 람다에 의해 만들어진 런타임 객체이다. 캡처 모드에 따라 클로저가 캡처된 자료의 복사본을 가질 수도 있고, 그 자료에 대한 참조를 가질 수도 있다.
- 클로저 클래스는 클로저를 만드는 데 쓰인 클래스를 말한다.
컴파일 타임에 존재하는 것(람다와 클로저 클래스)와 런타임에 존재하는 것(클로저)을 구분하는 것이 중요하다.
Item 31: Avoid default capture modes
C++11의 기본 캡처 모드는 두 가지이다.
- 참조에 의한(by-reference) 캡처 모드
- 값에 의한(by-value) 캡처 모드
참조에 의한 캡처 모드를 사용하는 클로저는 지역 변수 또는 람다가 정의된 범위에서 볼 수 있는 매개변수에 대한 참조를 가지게 된다. 람다에 의해 생성된 클로저의 수명이 그 지역 변수나 매개변수의 수명보다 오래 지속되면 클로저 안의 참조 대상을 잃는다.
void addDivisorFilter()
{
auto calc1 = computeSomeValue1();
auto calc2 = computeSomeValue2();
auto divisor = computeDivisor(calc1, calc2);
filters.emplace_back( // danger!
[&](int value) { return value % divisor == 0; } // ref to
); // divisor
} // will dangle!
divisor와 관련된 문제를 해결하는 방법은 값 캡처 모드를 사용하는 것이다.
filters.emplace_back( // now divisor
[=](int value) // can't dangle
{ return value % divisor == 0; }
);
그러나 값 캡처 모드도 다른 문제가 있다. 포인터를 값으로 캡처하면 이 포인터는 람다에 의해 생성된 클로저 안으로 복사되는데, 람다 바깥의 어떤 코드가 이 포인터를 delete로 삭제하지 않는다고 보장할 수 없기 때문이다.
class Widget {
public:
... // ctors, etc.
void addFilter() const; // add an entry to filters
private:
int divisor; // used in Widget's filter
};
캡처는 오직 람다가 생성된 범위 안에서 보이는 static이 아닌 지역 변수(또는 매개변수)에만 적용된다. 따라서 다음 코드는 컴파일되지 않는다.
void Widget::addFilter() const
{
filters.emplace_back(
[divisor](int value) // error! no local
{ return value % divisor == 0; } // divisor to capture
);
}
람다가 클로저 안에 캡처하는 것은 divisor가 아니라 Widget의 this 포인터다. 즉, 컴파일러는 값 캡처 [=]를 다음과 같이 취급한다.
void Widget::addFilter() const
{
auto currentObjectPtr = this;
filters.emplace_back(
[currentObjectPtr](int value)
{ return value % currentObjectPtr->divisor == 0; }
);
}
결과적으로 이 람다에서 만들어진 클로저의 유효성이 Wdiget 객체의 수명에 의해 제한된다.
이 문제는 캡처하려는 멤버의 지역 복사본을 만들어 이 복사본을 캡처하면 된다. 이는 값 캡처 모드([=])에서도 잘 동작한다.
void Widget::addFilter() const
{
auto divisorCopy = divisor; // copy data member
filters.emplace_back(
[divisorCopy](int value) // capture the copy
{ return value % divisorCopy == 0; } // use the copy
);
}
C++14에서 멤버를 캡처하기 위해 일반화된 람다(Item 32)를 사용하는 방법도 있다.
void Widget::addFilter() const
{
filters.emplace_back( // C++14:
[divisor = divisor](int value) // copy divisor to closure
{ return value % divisor == 0; } // use the copy
);
}
람다는 지역 변수나 매개변수 뿐 아니라 정적 저장소 수명 기간(static storage duration)를 가진 객체에도 의존할 수 있다. 전역 범위나 네임스페이스 범위에 정의된 객체와 클래스, 함수, 파일 안에서 static으로 선언된 객체들이 이에 해당한다. 그러나 값 캡처 모드는 이런 객체도 모두 캡처되어 격리되었다고 오해할 수 있다.
Item 32: Use init capture to move objects into closures
이동 전용 객체를 클로저 안으로 들여오려는 경우 값 캡처 모드나 참조 캡처 모드는 마땅치 않다. 그러나 C++14에서는 객체를 클로저 안으로 이동하는 수단을 직접 제공한다.
C++14는 새로운 캡처 메커니즘으로 초기화 캡처(init capture) 를 도입했다. 초기화 캡처로 표현할 수 없는 것 하나는 기본 캡처 모드인데, Item 31에 설명하듯 어짜피 기본 캡처 모드는 피해야 한다.
초기화 캡처로 다음과 같은 것들을 지정할 수 있다.
- 람다로부터 생성되는 클로저 클래스에 속한 자료 멤버의 이름
- 이 자료 멤버를 초기화하는 표현식
다음은 초기화 캡처를 통해 std::unique_ptr을 클로저 안으로 이동하는 예다.
class Widget { // some useful type
public:
...
bool isValidated() const;
bool isProcessed() const;
bool isArchived() const;
private:
...
};
auto pw = std::make_unique<Widget>(); // create Widget; see Item 21
// for info on std::make_unique
... // configure *pw
auto func = [pw = std::move(pw)] // init data mbr
{ return pw->isValidated() // in closure w/
&& pw->isArchived(); }; // std::move(pw)
=의 좌변은 클로저 클래스 안 자료 멤버(클로저에서 사용할)의 이름이고, 우변은 이것을 초기화하는 표현식이다. 좌변의 범위는 해당 클로저 클래스의 범위이고, 우변의 범위는 람다가 정의되는 지점의 범위와 동일하다. 즉, pw = std::move(pw)는 “클로저 안에서 자료 멤버 pw를 생성하되, 지역 변수 pw에 std::move를 적용한 결과로 이 자료 멤버를 초기화하라"는 의미이다.
만약 수정이 필요하지 않다면 지역 변수 pw는 필요하지 않다. 그냥 [pw = std::make_unique<Widget>()]와 같이 클로저 클래스의 멤버를 직접 초기화하면 된다.
C++11에서 람다를 고집한다면
std::bind를 사용해 비슷하게 흉내낼 수 있다. 그러나 Item 34에서std::bind보다는 람다를 선호하라고 조언한다.
Item 33: Use decltype on auto&& parameters to std::forward them
C++14에서 특별한 기능은 매개변수 명세에 auto를 사용한 람다이다. 람다의 클로저 클래스의 operator()를 템플릿 함수로 만들면 된다.
다음과 같은 람다 클래스가 있다고 하자.
auto f = [](auto x){ return func(normalize(x)); };
클로저 클래스의 함수 호출 연산자는 다음과 같은 모습으로 산출된다.
class SomeCompilerGeneratedClassName {
public:
template<typename T> // see Item 3 for
auto operator()(T x) const // auto return type
{ return func(normalize(x)); }
... // other closure class functionality
};
여기에서 람다는 매개변수 x를 항상 왼값으로 normalize()에 전달한다. 그런데 만약 normalize()가 왼값과 오른값을 다른 방식으로 처리한다면, 이 람다는 제대로 작성한 것이 아니다. 주어진 인수가 오른값이라면 오른값을 전달해야 한다.
그러려면 코드에서 바꿀 점이 두 가지이다.
x가 보편 참조여야 한다.x를std::forward를 통해normalize()에 전달해야 한다.
auto f = [](auto&& x)
{ return func(normalize(std::forward<???>(x))); };
일반적인 람다에서는 템플릿 함수처럼 사용할 타입 T가 없다. 람다가 산출하는 클래스 템플릿 operator()에는 T가 있지만, 람다에서는 이 T를 지정할 수 없다.
람다에 주어진 인수가 왼값인지 오른값인지는 매개변수 x의 타입을 decltype을 사용해 조사해보면 알 수 있다. 따라서 완벽 전달 람다는 다음과 같이 작성하면 된다.
auto f =
[](auto&& param)
{
return func(normalize(std::forward<decltype(param)>(param)));
};
또한 ...을 두 번 추가해주면 임의 개수의 매개변수들을 받아 완벽하게 전달하는 람다가 된다.
auto f =
[](auto&&... params) {
return
func(normalize(std::forward<decltype(params)>(params)...));
};
Item 34: Prefer lambdas to std::bind
프로그램의 어떤 지점에서 한 시간 후부터 30초간 소리를 내는 알람을 설정한다고 하자.
void setAlarm(Time t, Sound s, Duration d);
경보음은 미리 결정되지 않으며, 이런 경우 setAlarm()에 대한 소리만 지정하면 되는 인터페이스를 람다를 이용해 작성하면 편리할 것이다.
auto setSoundL =
[](Sound s)
{
using namespace std::chrono;
using namespace std::literals; // for C++14 suffixes
setAlarm(steady_clock::now() + 1h, // C++14, but
s, // same meaning
30s // as above
};
이와 같은 일을 하는 함수 객체를 std::bind로 작성해보자.
using namespace std::chrono; // as above
using namespace std::literals;
using namespace std::placeholders; // needed for use of "_1"
auto setSoundB =
std::bind(setAlarm, // "B" for "bind"
steady_clock::now() + 1h, // incorrect! see below
_1,
30s);
steady_clock::now() + 1h라는 표현식은 setAlarm()이 호출되는 시점에 평가된다. 그러나 std::bind 호출에서 인수 steady_clock::now() + 1h는 setAlarm()이 아니라 std::bind로 전달되며, 따라서 그 표현식이 평가되어 나오는 시간이 std::bind가 생성한 바인딩 객체에 저장된다. 즉, std::bind를 호출하고 한 시간이 지난 후 울리게 된다.
이를 바로잡으려면 이 표현식을 setAlarm() 호출 때까지 지연하라고 std::bind에 알려주어야 한다.
auto setSoundB =
std::bind(setAlarm,
std::bind(std::plus<>(), steady_clock::now(), 1h),
_1,
30s);
람다와 비교해보면 훨씬 더 복잡하게 구현해야 한다.
음량을 네 번째 매개변수로 받는 setAlarm() 오버로딩 버전을 추가한다고 하자.
void setAlarm(Time t, Sound s, Duration d, Volume v);
람다는 이전과 같이 인수 세 개짜리 setAlarm()이 호출된다. 반면 std::bind는 컴파일되지 않는다. 문제는 컴파일러로서 두 setAlarm() 중 어떤 것을 std::bind에 넘겨주어야 할지 결정할 수 없다는 것이다. 컴파일러가 알고 있는 것은 함수 이름뿐이며, 이로써는 중의성을 해소할 수 없다.
std::bind 호출이 컴파일되려면 setAlarm()을 적절한 함수 포인터 타입으로 캐스팅해야 한다. 이렇게 구현하면 람다와 std::bind의 차이점이 하나 더 생기는데, setSoundL에 대한 함수 호출 연산자 안에서 setAlarm() 호출은 컴파일러가 통상적인 방식으로 인라이닝할 수 있는 보통의 함수 호출이다. 그러나 std::bind 호출은 setAlarm()을 가리키는 함수 포인터를 전달하므로, setSoundB를 통한 setAlarm() 호출은 setSoundL을 통한 호출에 비해 인라인될 가능성이 낮다.
std::bind를 사용하는 코드는 람다에 비해 읽기 힘들고 표현력이 낮다. 또한 효율성이 떨어질 가능성이 있다.
Item 35: Prefer task-based programming to thread- based
doAsyncWork() 함수를 비동기적으로 실행한다고 하면 두 가지 방법이 존재한다.
-
thread-based:
std::thread객체를 생성해 이 객체에서doAsyncWork()를 실행하는 것int doAsyncWork(); std::thread t(doAsyncWork); -
task-based:
doAsyncWork()를std::async에 넘겨주는 것auto fut = std::async(doAsyncWork);std::async에 전달된 함수 객체는 하나의 과제(task)로 간주된다.
과제 기반 접근방식에서는 반환값에 접근이 가능하다. std::async가 돌려주는 future 객체에 get()이라는 멤버 함수가 있기 때문이다. get() 함수는 doAsyncWork()가 예외를 방출하는 경우 더욱 중요해진다. get()을 통해서 그 예외에 접근할 수도 있기 때문이다. 스레드 기반 접근방식은 doAsyncWork()가 예외를 던지면 프로그램도 죽는다.
동시성 C++ 소프트웨어에서 스레드는 세 가지 의미로 사용된다.
- 실제 계산을 수행하는 스레드를 뜻하는 하드웨어 스레드. CPU 코어 당 하나 이사의 하드웨어 스레드를 제공한다.
- OS가 하드웨어 스레드들에서 실행되는 모든 프로세서와 일정을 관리하는 데 사용하는 소프트웨어 스레드. 대체로 하드웨어 스레드보다 많은 소프트웨어 스레드를 생성할 수 있다.
- C++ 라이브러리의
std::thread. 하나의 C++ 프로세스 안에서std::thread객체는 핸들로 작용한다.std::thread는 널(null) 핸들을 나타내기도 한다. 즉,std::thread객체가 어떤 소프트웨어 스레드에도 대응되지 않을 수 있다.
소프트웨어 스레드는 제한된 자원이다. 즉, 시스템이 제공할 수 있는 것보다 많은 소프트웨어 스레드를 생성하면 std::system_error 예외가 발생한다.
과다구독(oversubscription) 떄문에 문제가 발생할 수 있다. 과다구독이 발생하면 스레드 스케줄러는 하드웨어상의 실행 시간을 여러 조각으로 나누어 소프트웨어 스레드들에게 배분한다. 한 소프트웨어 스레드에 부여된 시간이 끝나고 다른 소프트웨어 스레드를 시작할 때 컨텍스트 스위칭(context switching)이 수행되는데, 이 작업은 시스템 전반적인 스레드 관리 부담을 증가시킨다.
과다구독이란 실행 준비가 된(차단되지 않은) 소프트웨어 스레드가 하드웨어 스레드보다 많은 상황을 가리킨다.
다음번 소프트웨어 스레드가 실행될 하드웨어 스레드가 이전 시간 조각(time slice)에서 그 소프트웨어 스레드가 실행된 하드웨어 스레드와 다른 코어에 있는 경우 컨텍스트 스위칭 비용이 더 커진다.
- 일반적으로 CPU 캐시는 그 소프트웨어 스레드에 대해 차갑다.(cold: 그 소프트웨어 스레드에 유용한 자료와 명령이 거의 없음을 뜻함)
- 그 코어에서 ‘새로운’ 소프트웨어 스레드를 실행하면 그 코어에서 실행되던, 그리고 다음번에도 그 코어에서 실행될 가능성이 큰 ‘기존’ 스레드들에 대한 CPU 캐시들이 오염된다.
이런 문제들을 떠넘기는 방법은 std::async를 사용하는 것이다. std::async는 스레드 관리 책임을 프로그래머로부터 C++ 표준 라이브러리로 옮긴다. 이렇게 하면 가용 스레드 부족 때문에 예외를 받을 가능성이 크게 줄어든다.
std::async에서도 GUI 스레드 반응성이 여전히 문제가 될 수 있다. 스케줄러는 프로그래머의 스레드 중 반응성이 좋아야 하는 스레드가 어떤 것인지 알 수 없기 때문이다. 이 경우 std::launch::async라는 정책을 std::async에 넘겨주어 실행하고자 하는 함수가 실제로 현재 스레드와는 다른 스레드에서 실행되게 할 수 있다(Item 36).
스레드를 직접 다루는 게 적합한 경우도 있다.
- 기본 스레드 적용 라이브러리의 API에 접근해야 하는 경우
- 애플리케이션 스레드 사용량을 최적화해야 하는, 그리고 할 수 있어야 하는 경우
- C++ 동시성 API가 제공하는 것 이상의 스레드 적용 기술을 구현해야 하는 경우
Item 36: Specify std::launch::async if asynchronicity is essential
std::async 호출은 함수를 어떤 실행 정책(launch policy)에 따라 실행한다는 좀 더 일반적인 의미를 갖는다.
함수 f()를 실행할 때,
std::launch::async를 지정하면f()는 반드시 비동기적으로(다른 스레드에서) 실행된다.std::launch::deferred를 지정하면f()는std::async가 돌려준std::future에 대해get()이나wait()이 호출될 때에만 실행될 수 있다.
기본 실행 정책은 이 둘을 OR 결합한 것이다. 결과적으로 f()는 비동기적으로 실행될 수도 있고 동기적으로 실행될 수도 있다.1
기본 실행 정책을 사용하면 흥미로운 경우가 있다. 예를 들어 다음 문장이 스레드 t에서 실행된다고 하자.
auto fut = std::async(f); // run f using default launch policy
f()가 지연 실행될 수도 있으므로f()가t와 동시에 실행될지 예측하는 것이 불가능하다.f()가fut에 대해get()이나wait()을 호출하는 스레드와는 다른 스레드에서 실행될지 예측하는 것이 불가능하다.- 프로그램의 모든 가능한 경로에서
fut에 대한get()이나wait()호출이 일어난다는 보장이 없을 수 있으므로,f()가 반드시 실행될 것인지 예측하는 것이 불가능할 수도 있다.
기본 실행 정책 스케줄링 유연성이 thread_local 변수들의 사용과는 잘 맞지 않는 경우도 있다. f()에 스레드 지역 저장소(TLS: Thread-Local Storage)를 읽거나 쓰는 코드가 있다고 할 때, 이 코드가 어떤 스레드의 지역 변수에 접근할지 예측할 수 없기 때문이다.
지연된 작업(deffered task)에 wait_for()나 wait_until()을 호출하면 std::future_status::deferred라는 값이 반환되기 때문에, 언젠가는 끝날 것처럼 보이는 다음 루프가 실제로는 무한히 수행될 수도 있다.
using namespace std::literals; // for C++14 duration suffixes; see Item 34
void f() { // f sleeps for 1 second, then returns
std::this_thread::sleep_for(1s);
}
auto fut = std::async(f); // run f asynchronously (conceptually)
while (fut.wait_for(100ms) != // loop until f has finished running...
std::future_status::ready) // which may never happen!
{
...
}
이러한 문제는 std::async 호출이 돌려주는 future 객체를 이용해 해당 작업(task)가 지연되었는지 확인하고, 지연되었다면 타임아웃 기반 루프에 진입하지 않도록 하여 해결할 수 있다.
if (fut.wait_for(0s) == // if task is deferred...
std::future_status::deferred)
{
// ...use wait or get on fut
... // to call f synchronously
}
결론은 어떤 작업에 대해 기본 실행 정책과 함께 std::async를 사용하는 것은 다음 조건들이 모두 성립할 때만 적합하다는 것이다.
- 작업이
get()이나wait()을 호출하는 스레드와 반드시 동기적으로 실행되어야 하는 것은 아니다. - 여러 스레드 중 어떤 스레드의
thread_local변수들을 읽고 쓰는지가 중요하지 않다. std::async가 돌려준future객체에 대해get()이나wait()이 반드시 호출된다는 보장이 있거나 작업이 전혀 실행되지 않아도 된다.- 작업이 지연 상태일 수도 있다는 점이
wait_for()나wait_until()을 사용하는 코드에 반영되어 있다.
이 조건이 성립하지 않는다면 std::async가 작업을 비동기적으로 실행되도록 강제할 필요가 있다. std::launch::async를 인수로 지정하는 것이다. std::launch::async를 명시적으로 지정하지 않도록 다음과 같은 템플릿을 만들 수도 있다.
template<typename F, typename... Ts>
inline
auto // C++14
reallyAsync(F&& f, Ts&&... params)
{
return std::async(std::launch::async,
std::forward<F>(f),
std::forward<Ts>(params)...);
}
Item 37: Make std::threads unjoinable on all paths
모든 std::thread 객체는 합류 가능(joinable) 상태이거나 합류 불가능(unjoinable) 상태이다.
합류가 불가능한 std::thread는 다음과 같은 것들이 있다.
- 기본 생성된
std::thread - 다른
std::thread객체로 이동된 후의std::thread객체 join()에 의해 합류된std::threaddetach()에 의해 탈착된std::thread
std::thread의 합류 가능성이 중요한 이유 중 하나는, 만일 합류 가능한 스레드의 소멸자가 호출되면 프로그램이 종료된다는 것이다.
constexpr auto tenMillion = 10000000; // see Item 15 for constexpr
bool doWork(std::function<bool(int)> filter, // returns whether computation was performed
int maxVal = tenMillion) // see Item 2 for std::function
{
std::vector<int> goodVals; // values that satisfy filter
std::thread t([&filter, maxVal, &goodVals] // populate
{ // goodVals
for (auto i = 0; i <= maxVal; ++i)
{ if (filter(i)) goodVals.push_back(i); }
});
auto nh = t.native_handle(); // use t's native handle to set t's priority
...
if (conditionsAreSatisfied()) {
t.join(); // let t finish
performComputation(goodVals);
return true; // computation was performed
}
return false; // computation was not performed
}
conditionsAreSatisfied()가 true를 돌려주면 문제가 없지만, false를 돌려주거나 예외를 던지면 실행의 흐름이 doWork() 끝에 도달해 std::thread 객체 t의 소멸자가 호출되는데, 문제는 이 t가 여전히 합류 가능한 상태라는 것이다. 때문에 프로그램 실행이 종료된다.
std::thread의 소멸자가 이렇게 행동하는 데에는 이유가 있다.
- An implicit join.
std::thread의 소멸자가 비동기 기본 실행 스레드의 완료를 기다리는 것이다. 이는 실제로 추적하기 어려운 퍼포먼스 이상(performance anomaly)들을 나타날 수 있다. - An implicit detach.
std::thread소멸자가std::thread객체와 기본 실행 스레드 사이 연결을 끊게 하는 것이다. 이는 더 심각하다. 위 예에서goodVals는 지역 변수인데, 람다 참조에 의해 캡처되어 자신의 본문에서 수정한다. 만약conditionsAreSatisfied()가false를 돌려주어doWork()가 반환되면 지역 변수들이 파괴되지만, 해당 스레드는doWork()호출 지점에서 계속 실행된다. 만약 다음 호출될 함수가f()라면goodVals는f()스택 프레임에 있을 것이며,push_back()호출은f()스택 프레임에 있는 메모리 내용이 갑자기 변하는 기현상이 발생하게 된다.
따라서 std::thread 객체를 사용할 때 그 객체가 정의된 범위 바깥의 모든 경로에서 합류 불가능하게 만드는 것은 프로그래머의 책임이다.
한 범위 바깥으로 나가는 모든 경로에서 어떤 동작이 반드시 수행되어야 할 때 흔히 사용하는 접근방식은, 그 동작을 지역 객체 소멸자 안에 넣는 것이다. 이런 객체를 RAII(Resource Acquisition Is Initialize) 객체라 한다. std::thread에 대해서도 이런 접근방식을 사용해 스레드가 합류 가능 또는 불가능하도록 만들 수 있다.
Item 38: Be aware of varying thread handle destructor behavior
합류 가능한 std::thread는 기본 시스템 스레드에 대응된다. 이와 비슷하게 지연되지 않은 작업(task)도 시스템 스레드에 대응된다. 따라서 std::thread 객체와 future 객체 모두 시스템 스레드에 대한 핸들이라 할 수 있다.
std::thread와 future 객체의 소멸자들은 다르게 행동한다. 합류 가능한 std::thread를 파괴하면 프로그램이 종료되나, future 객체의 소멸자는 어떨때는 마치 암묵적으로 join()을 수행한 결과를 내고, 어떨 때는 암묵적으로 detach()를 수행한 결과를 낸다.
future 객체는 피호출자가 결과를 호출자에게 전송하는 통신 채널의 끝이다. 피호출자의 결과를 std::promise나 std::future에 저장할 수 없으므로, 둘 다 바깥에 있는 장소에 결과를 담아야 한다. 이 장소가 바로 공유 상태(shared state) 다.

이런 공유 상태가 중요한 것은, future 객체 소멸자의 행동을 그 future 객체와 연관된 공유 상태가 결정하기 때문이다.
std::async를 통해 시작된 지연 작업에 대한 공유 상태를 참조하는 마지막future객체의 소멸자는 작업이 완료될 때까지 차단된다.- 다른 모든
future객체의 소멸자는 그냥 해당future객체를 파괴한다.
정상 행동(future 객체의 소멸자가 future 객체를 파괴하는 것)에 대한 예외는 다음 조건들을 모두 만족하는 future 객체에 대해서 일어난다.
future객체가std::async호출에 의해 생성된 공유 상태를 참조한다.- 작업의 실행 정책이
std::launch::async이다. future객체가 공유 상태를 참조하는 마지막future객체이다.std::future의 경우 이 조건이 항상 성립하며,std::shared_future의 경우,future객체가 파괴되는 동안 같은 공유 상태를 다른std::shared_future가 참조하고 있다면, 파괴되는future객체는 정상 행동을 따른다.
이 모든 조건이 성립할 때 future 객체의 소멸자는 비동기적으로 실행되는 작업이 완료될 때까지 소멸자의 실행이 블로킹된다는 것이다. 즉, std::async로 생성한 작업을 실행하는 스레드에 대해 암묵적 join()을 호출하는 것이다.
소멸자의 특별한 행동은 공유 상태가 std::async 호출에서 비롯된 경우에만 일어날 수 있다. 그러나 이외의 여러 원인으로도 공유 상태가 생성될 수 있다. 그 중 하나가 std::packaged_task다. std::packaged_task 객체는 주어진 함수를 비동기적으로 실행할 수 있도록 ‘포장’하는데, 포장된 함수의 실행 결과는 공유 상태에 저장된다. 그 공유 상태를 참조하는 미래 객체를 얻으려면 std::packaged_task의 get_future() 함수를 호출하면 된다. 이 경우 future 객체가 std::async 호출로 만들어진 공유 상태를 참조하지 않으므로, 해당 소멸자는 정상적으로 행동한다.
Item 39: Consider void futures for one-shot event communication
스레드 간 통신을 처리하는 방법 중 하나는 조건 변수(condition variable)을 사용하는 것이다. 조건을 검출하는 작업을 검출 작업(detecting task)라 부르고, 그 조건에 반응하는 작업을 반응 작업(reacting task)라 부르기로 할 때, 반응 작업은 하나의 조건 변수를 기다리고, 검출 작업은 이벤트가 발생하면 그 조건 변수를 통지하는 방식이다.
std::condition_variable cv; // condvar for event
std::mutex m; // mutex for use with cv
... // detect event
cv.notify_one(); // tell reacting task
이벤트 발생을 알려줄 반응 작업이 여러 개라면 notify_all() 사용이 적합하다. 반응 작업의 경우 조건 변수에 대해 wait()을 호출하기 전 먼저 std::unique_lock 객체를 통해 뮤텍스를 잠가야 한다.
... // prepare to react
{ // open critical section
std::unique_lock<std::mutex> lk(m); // lock mutex
cv.wait(lk); // wait for notify; this isn't correct!
... // react to event (m is locked)
} // close crit. section; unlock m via lk's dtor
... // continue reacting (m now unlocked)
이 코드에서 처리해야 할 문제점이 있다.
-
만일 반응 작업이
wait()을 실행하기 전 검출 작업이 조건 변수를 먼저 통지하면 반응 작업이 멈추게 된다(hang). -
wait()호출문은 가짜 기상(wakeup)을 고려하지 않는다. 조건 변수를 기다리는 코드가 조건 변수가 노티하지 않았는데 깨어날 수 있는 것은 스레드 적용 API들에서 흔히 있는 일이다. 이런 일을 가짜 기상이라고 한다. 이를 제대로 처리하려면 기다리던 조건이 실제로 발생했는지 확인해야 하며, 기상 후 먼저 확인해야 한다.cv.wait(lk, []{ return whether the event has occurred; });
bool 플래그를 추가하여 이벤트 발생을 검출할 수 있을 것이다. 반응 스레드에서는 이 플래그를 폴링한다. 플래그가 설정되어 있으면 기다리던 이벤트가 발생했다는 뜻이다. 그러나 폴링 비용이 단점이다.
조건 변수와 플래그를 같이 사용한다고 하면 가짜 기상 문제와 폴링 비용은 줄일 수 있지만, 조건 변수를 노티해야 할 뿐만 아니라 bool 플래그도 설정해야 한다. 반응 작업에서는 이 bool 플래그를 점검해야 한다. 즉, 검출 작업에서 이벤트가 발생했음을 플래그를 설정해 반응 작업에 알려주지만, 반응 작업이 그 플래그를 점검하게 하려면 먼저 조건 변수를 노티해 반응 작업을 깨워야 한다.
조건 변수와 뮤텍스, 플래그를 사용할 필요 없는 한 가지 대안은, 검출 작업이 설정한 future 객체를 반응 작업이 기다리게 하는 것이다. 전송 단자가 std::promise이고 수신 단자가 future인 객체를 사용할 수 있다.
검출 작업에는 std::promise 객체를 하나 두고, 반응 작업에는 이에 대응되는 future 객체 하나를 둔다. 기다리는 이벤트가 발생했음을 인식하면 검출 작업은 자신의 std::promise를 설정한다. 그 동안 반응 작업은 자신의 future 객체에 대해 wait()을 호출한 상태이다. wait() 호출은 std::promise가 설정될 때까지 차단된다.
그런데 std::promise와 future 객체는 모두 타입 매개변수를 요구하는 템플릿이다. 이 타입 매개변수는 통신 채널을 통해 전송할 자료 타입을 뜻한다. 그러나 지금은 전송할 자료가 없다. 따라서 검출 작업에서는 std::promise<void>, 반응 작업에서는 std::future<void>나 std::shared_future<void>를 사용하면 된다.
다음과 같은 std::promise 객체가 있을 때
std::promise<void> p;
검출 작업의 코드는 다음과 같으며며
... // detect event
p.set_value(); // tell reacting task
반응 작업에 코드는 다음과 같다.
... // prepare to react
p.get_future().wait(); // wait on future corresponding to p
... // react to event
이 설계는 뮤텍스가 필요하지 않으며, 반응 작업이 wait()로 대기하기 전 검출 작업이 자신의 std::promise를 설정해도 동작하며, 가짜 기상(wakeup)도 없다.
이러한 방식을 사용하게 되면 std::promise와 future 객체 사이 공유 상태가 있게 되며, 대체로 이 공유 상태는 동적으로 할당된다. 따라서 이 설계는 힙 기반 할당 및 해제 비용을 유발한다.
또한 std::promise를 한 번만 설정할 수 있다. 즉, std::promise와 future 객체 사이 통신 채널은 여러 번 되풀이해 사용할 수 없는 단발성(one-shot) 메커니즘이다.
결과적으로 스레드를 한 번만 중지(suspend)한다면, void, future 객체를 이용하는 설계는 합리적인 선택이다.
Item 40: Use std::atomic for concurrency, volatile for special memory
std::atomic 객체가 생성되면 이 객체에 대한 연산은 마치 뮤텍스로 보호되는 임계 영역(critical section) 안에서 수행되는 것처럼 작동한다. 그러나 이러한 원자적 연산은 실제로 뮤텍스를 사용할 때보다 좀 더 효율적인 기계어 명령들로 구현되는 것이 보통이다.
std::atomic<int> ai(0); // initialize ai to 0
ai = 10; // atomically set ai to 10
std::cout << ai; // atomically read ai's value
++ai; // atomically increment ai to 11
--ai; // atomically decrement ai to 10
이 문장들을 실행하는 동안 ai를 읽는 다른 스레드들이 보게 되는 값은 0이나 10, 11 뿐이다.
예제에서 마지막 두 문장의 행동(++ai, --ai)를 주목할 필요가 있다. 증가 연산이나 감소 연산은 RMW(Read-Modify-Write) 연산이지만, 각각 원자적으로 수행된다. 따라서 std::atomic 객체가 생성되면, 그 객체에 대한 모든 멤버 함수는 RMW 연산들을 수행하는 멤버 함수도 다른 스레드들에게 반드시 원자적으로 보이게 된다.
반면 volatile을 사용하는 코드는 다중 스레드 컨텍스트에서 거의 아무것도 보장하지 않는다.
volatile int vi(0); // initialize vi to 0
vi = 10; // set vi to 10
std::cout << vi; // read vi's value
++vi; // increment vi to 11
--vi; // decrement vi to 10
이 코드 실행 중 vi의 값을 다른 스레드들이 읽는다면, 그 스레드들은 어떤 값이라도 볼 수 있다. 이런 코드는 의도되지 않은 행동을 유발한다(data race).
std::atomic<int> ac(0); // "atomic counter"
volatile int vc(0); // "volatile counter"
/*----- Thread 1 ----- */ /*------- Thread 2 ------- */
++ac; ++ac;
++vc; ++vc;
두 스레드의 실행이 끝난 후 ac의 값은 반드시 2이다. 그러나 vc의 값은 2일수도 있고 아닐수도 있다. 해당 연산이 원자적으로 실행되지 않았기 때문이다.
필요한 값이 준비되었음을 알려주는 코드가 있다고 하자.
std::atomic<bool> valAvailable(false);
auto imptValue = computeImportantValue(); // compute value
valAvailable = true; // tell other task it's available
컴파일러는 두 할당문을 단지 서로 독립적인 변수에 대한 두 할당으로 볼 뿐이다. 일반적인 규칙으로 이런 무관한 할당들의 순서를 컴파일러가 임의로 바꾸는 것은 적법하다. 순서를 바꾸면 코드가 더 빨리 실행되는 경우가 있기 때문이다.
그러나 std::atomic을 사용하면 코드 순서 재배치에 대한 제약들이 생기며, 이런 제약 중 하나는 소스 코드에서 std::atomic 변수를 기록하는 문장 이전에 나온 그 어떤 코드도 그 문장 이후에 실행되지 않아야 한다는 것이다. volatile은 이런 코드 재배치 제약이 가해지지 않는다.
다음 코드는 컴파일러가 둘째 줄 y에 대한 할당문을 제거해 오브젝트 코드를 최적화할 수 있다.
auto y = x; // read x
y = x; // read x again
이런 최적화는 메모리가 보통의 방식으로 행동할 때에만 유효하다. 그러나 특별한 메모리는 이런 식으로 행동하지 않는다. 특별한 메모리 중 흔히 접하는 것은 메모리 대응 입출력(memory-mapped I/O)에 쓰이는 메모리일 것이다. 만일 x가 온도계가 보고하는 값이라면, 두 번째 x 읽기는 불필요하지 않다. 첫 번째 읽기와 두 번째 읽기 사이 온도가 변했을 수 있기 때문이다.
따라서 volatile은 해당 코드가 특별한 메모리를 다룬다는 점을 컴파일러에 알려주는 수단이다. 즉, 컴파일러는 “이 메모리에 대한 연산들에는 그 어떤 최적화도 수행하지 말라"는 지시라 생각한다. 만약 x가 특별한 메모리에 해당한다면 volatile로 선언해야 한다.
Item 41: Consider pass by value for copyable parameters that are cheap to move and always copied
Widget의 addName() 함수의 구현의 방식 세 가지를 보자.
class Widget { // Approach 1:
public: // overload for
void addName(const std::string& newName) // lvalues and rvalues
{ names.push_back(newName); }
void addName(std::string&& newName)
{ names.push_back(std::move(newName)); }
...
private:
std::vector<std::string> names;
};
class Widget { // Approach 2:
public: // use universal reference
template<typename T>
void addName(T&& newName)
{ names.push_back(std::forward<T>(newName)); }
...
};
class Widget { // Approach 3:
public: // pass by value
void addName(std::string newName)
{ names.push_back(std::move(newName)); }
...
};
- 오버로딩 구현
- 같은 일을 하는 함수 두 개를 작성해야 한다. 오브젝트 코드에 실제 두 개의 함수가 존재하게 된다.
- 왼값의 경우 복사 1회
- 오른값의 경우 이동 1회
- 보편 참조
- 보편 참조로는 전달할 수 없는 타입들(Item 30)이 있고, 클라이언트가 부적절한 타입 인수를 전달하면 컴파일러가 난해한 오류 메시지를 출력할 수 있다(Item 27).
- 왼값의 경우 복사 1회
- 오른값의 경우 이동 1회
- 값 전달
newName은 인수가 왼값일 때에만 복사, 오른값일 때에는 이동 생성에 의해 생성된다.- 왼값의 경우 복사 1회 + 이동 1회
- 오른값의 경우 이동 2회
-
값 전달을 사용하라가 아닌 고려하라는 것일 뿐이다.
-
복사 가능 매개변수에 대해서만 값 전달을 고려해야 한다. 복사할 수 없는 매개변수느 반드시 이동 전용 타입일 것이다. 이동 전용 타입은 왼값 인수를 위한 오버로딩을 따로 둘 필요가 없다. 이런 타입에서 왼값의 복사는 복사 생성자 호출로 이어지는데, 이동 전용 타입에서는 복사 생성자가 비활성화되어 있기 때문이다. 따라서 오른값 인수를 위한 오버로딩만 제공하면 되며, 이 경우 오른값 참조를 받는 버전 하나만 있으면 된다.
-
값 전달은 이동이 저렴한 매개변수에 대해서만 고려해야 한다. 이동이 저렴한 경우 이동이 한 번 더 일어나도 큰 문제가 되지 않는다. 그러나 비용이 크다면, 이는 불필요한 복사를 수행하는 것과 비슷하다.
-
값 전달은 항상 복사되는 매개변수에 대해서만 고려해야 한다.
addName()이 매개변수names컨테이너로 복사하기 전 이름이 길이를 점검한다면,names에 아무것도 추가하지 않는 경우에도newName의 생성과 파괴 비용을 유발한다.class Widget { public: void addName(std::string newName) { if ((newName.length() >= minLen) && (newName.length() <= maxLen)) { names.push_back(std::move(newName)); } } ... private: std::vector<std::string> names; };
이동이 저렴하더라도 값 전달이 적합하지 않은 경우가 있다. 이는 함수가 매개변수를 복사하는 방식이 두 가지이기 때문이다.
- 생성을 통한 복사
- 할당을 통한 복사
패스워드를 나타내는 Password 클래스가 있다고 하자.
class Password {
public:
explicit Password(std::string pwd) // pass by value construct text
: text(std::move(pwd)) {}
void changeTo(std::string newPwd) // pass by value assign text
{ text = std::move(newPwd); }
...
private:
std::string text; // text of password
};
다음 코드는 생성자에서 값 전달이 쓰이므로 std::string 이동 생성 1회의 비용이 발생한다.
std::string initPwd("Supercalifragilisticexpialidocious");
Password p(initPwd);
패스워드를 바꾸기 위해 다음 코드를 추가했다고 하자.
std::string newPassword = "Beware the Jabberwock";
p.changeTo(newPassword);
changeTo()가 매개변수 newPwd를 복사하려면 할당을 수행해야 하며, 이러면 함수의 값 전달 접근방식 때문에 비용이 커질 수 있다. changeTo()에 전달되는 인수는 왼값이다. 따라서 매개변수 newPwd가 생성될 때 호출되는 것은 std::string의 복사 생성자다. 이 생성자는 새로운 패스워드를 담을 메모리를 할당한다. 그 다음 newPwd가 text로 이동 할당되는데, 이에 의해 text가 차지하고 있던 메모리가 해제된다. 즉, 새 패스워드를 담을 메모리 할당과 기존 메모리가 차지하던 메모리를 해제하는 동적 메모리 관리 동작이 두 번 일어난다.
기존 패스워드가 새로운 패스워드보다 길다고 할 때, 메모리를 할당하거나 해제할 필요가 없다. 오버로딩 접근방식을 사용하면 할당과 해제를 생략할 수 있다.
void changeTo(const std::string& newPwd) // the overload for lvalues
{
text = newPwd; // can reuse text's memory if
} // text.capacity() >= newPwd.size()
이처럼 매개변수가 할당으로 복사될 때는 값 전달 접근방식 비용 분석이 복잡해진다. 따라서 매개변수 타입에 대해 값 전달 방식이 충분히 효율적인 코드를 산출하는 것이 확실치 않다면 오버로딩이나 보편 참조를 사용하자.
또한 값 전달에서는 잘림 문제(slicing problem)이 발생할 수 있다. 함수가 기반 클래스 타입이나 이로부터 파생된 임의의 타입의 매개변수를 받는 경우 그 매개변수를 값 전달 방식으로 선언하지 않는 것이 좋다. 만일 이런 매개변수를 값 전달로 선언하면, 파생 타입의 객체가 전달되었을 때 그 객체의 파생 클래스 부분이 잘려 나가기(slice off) 때문이다.
Item 42: Consider emplacement instead of insertion
std::vector<std::string> vs; // container of std::string
vs.push_back("xyzzy"); // add string literal
std::vector의 push_back()은 다음과 같다.
template <class T, // from the C++11 Standard
class Allocator = allocator<T>>
class vector {
public:
...
void push_back(const T& x); // insert lvalue
void push_back(T&& x); // insert rvalue
...
};
push_back()으로 넘겨주는 것은 문자열 리터럴이다. 따라서 컴파일러는 인수의 타입과 push_back()이 받는 매개변수 타입 불일치를 해소하기 위해 다음과 같은 코드를 산출한다.
- 문자열 리터럴 “xyzzy"로부터 임시
std::string객체가 생성된다. 이 객체를 temp라 하자. temp의 생성이 첫 번째std::string의 생성이다. - temp가
push_back()의 오른값 오버로딩으로 전달된다. temp는 오른값 참조 매개변수x에 바인딩된다. 그 다음std::vector를 위한 메모리 안에서x의 복사본이 생성된다. 이 생성이 두 번째std::string의 생성이다. push_back()이 반환된 즉시 temp가 파괴되어std::string소멸자가 실행된다.
두 번째에서 std::vector 안에 std::string 객체를 생성하는 코드에 문자열 리터럴을 직접 전달할 수 있다면 temp의 생성과 파괴를 피할 수 있을 것이다.
지금 필요한 것은 emplace_back()이다. emplace_back()은 주어진 인수를 이용해 std::vector 안에서 직접 std::string을 생성한다. 임시 객체는 관여하지 않는다.
vs.emplace_back("xyzzy"); // construct std::string inside
// vs directly from "xyzzy"
이런 생성 삽입(emplacement) 함수들이 삽입 함수들보다 성능이 뛰어난 것은 인터페이스가 더 유연하기 때문이다. 삽입 함수들은 삽입할 객체를 받지만, 생성 삽입 함수는 삽입할 객체의 생성자를 위한 인수들을 받는다. 따라서 생성 삽입 함수들은 삽입 함수에서 꼭 필요할 수 있는 임시 객체의 생성과 파괴가 없다.
다음 세 조건이 모두 성립하면 거의 항상 생성 삽입의 성능이 더 좋다.
- 추가할 값이 컨테이너에 할당되는 것이 아니라 컨테이너 안에 생성된다.
- 추가할 인수 타입(들)이 컨테이너가 담는 타입과 다르다.
- 컨테이너가 기존 값과의 중복 때문에 새 값을 거부할 우려가 별로 없다.
생성 삽입 함수들의 주목할 점 중 하나는 explicit 생성자들과의 상호작용 방식이다.
정규표현식들을 담을 컨테이너를 만들어보자.
std::vector<std::regex> regexes;
다음과 같이 비슷한 초기화 구문이 다른 결과를 낸다.
std::regex r1 = nullptr; // error! won't compile
std::regex r2(nullptr); // compiles
r1을 초기화하는 데 쓰인 구문은 복사 초기화이다. 반면 r2를 초기화하는 데 쓰인 구문은 직접 초기화이다. explicit 생성자에서는 복사 초기화를 사용할 수 없지만 직접 초기화는 사용할 수 있다. 따라서 r2 초기화 문장은 컴파일된다.
생성 삽입 함수는 직접 초기화를 사용한다. 따라서 explicit 생성자를 지원한다. 삽입 함수는 복사 생성자를 사용하므로 explicit 생성자를 지원하지 않는다.
regexes.emplace_back(nullptr); // compiles. Direct init permits use of explicit std::regex ctor taking a pointer
regexes.push_back(nullptr); // error! copy init forbids use of that ctor
즉, 생성 삽입 함수는 삽입 함수라면 거부당했을 타입 변환들을 수행할 수도 있다.